星型模式:业务模型扩展字段存储
构建业务模型时,通常模型会设置扩展信息,存储上一般使用JSON格式存储到db中。JSON虽然有较好的扩展性,但并没有结构化存储的类型和非空等约束,且强依赖代码中写入/读取时进行序列化/反序列化操作, 当扩展信息结构简单且不作为查询条件时使用JSON可以满足需求,但有些场景要求根据扩展字段进行查询,虽然有类似JSON_CONTAINS关键字匹配JSON内部字段,但不是所有db及其版本都支持JSON加内部索引的,且SQL语句复杂,难以维护。
本文介绍了一种业务模型扩展字段的存储方式以及使用方法。
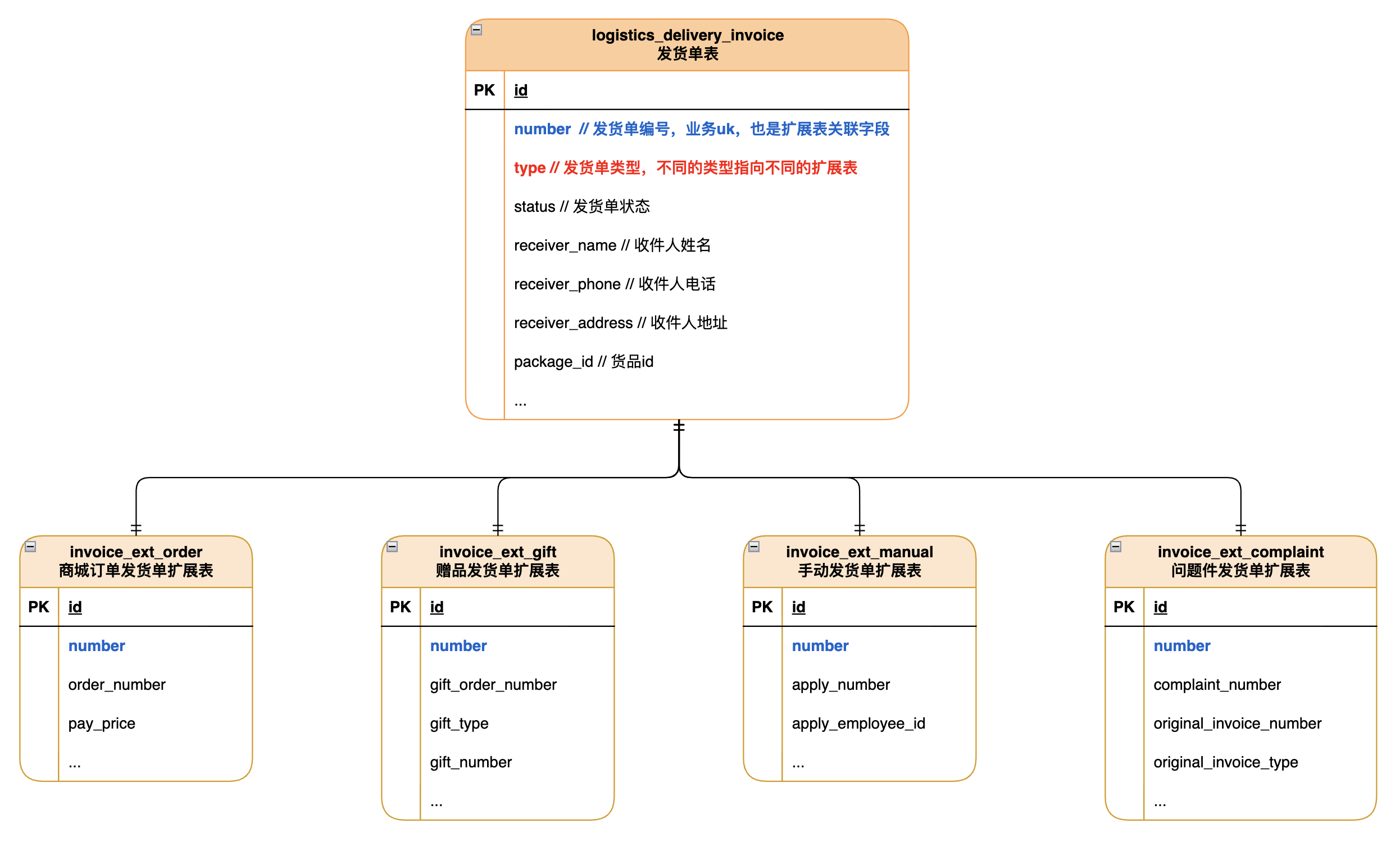
设想一个物流发货场景,物流系统接收公司内部不同业务线的发货请求生成发货单,不同业务线的发货单数据有不同的扩展字段。 比如用户商城下单产生一个发货单,发货单需要关联订单号、支付金额;用户有赠品需要发货,发货单需要关联赠品订单号、赠品类型、赠品编号; 运营手动给某个用户发货,发货单需要关联发货审批编号,发货申请人;用户之前发的物流有问题,提起申诉,需要重新发货,问题件类型的发货单需要关联申诉编号、原发货单号、原发货类型。
直接在发货单主表使用非结构化的JSON字段存储以上数据,不优雅,物流域其实不关心上游扩展字段,其主表也不应参杂其余域的信息;作为物流域主表其查询写入肯定会很频繁,无脑加扩展字段后期会导致主表膨胀,查询写入效率降低。
因此,我们只在发货单主表logistcs_delivery_invoice存储物流域数据,扩展数据根据发货单类型“路由”到不同的扩展表,再根据发货单编号关联其中的数据,其结构类似与一个星型。 在扩展表中,可以直接使用结构化的存储,方便后续查询。 其实体关系图如下:
由于涉及多个表,在每次生成发货单时,必须使用事务保证两者插入的原子性,而在分库分表的情况下扩展表还要冗余分片字段,且新接入类型需要新建扩展表。 同时,如果想查出带扩展字段的发货单数据,只依赖db就必须联表查询,或者引入异构数据源,如ElasticSearch:
将发货单表和扩展表按发货单号和类型关联,在ES中构建出一张“宽表”,后续的查询操作基于ES进行。 而ES是准实时的,数据插入到查询需要1s左右的时间,在物流场景下由于发货单生成本身是异步的,且实时性要求不高,1s的延迟是可以接受的。 而其他业务场景数据直接由B端运营人员或C端用户直接创建时,一种妥协是让前端在发完新建数据请求后页面转圈圈1s,对于用户来说体验不会太差,也能很大程度上保证后续查询不会查不到数据。 当然,异构数据的同步必定要有巡检任务来校验数据一致性,包括要完善产生不一致后的主动修复与监控告警机制,同时也要提供手动同步接口,在程序中 可以通过特性开关的方式来控制查询是走ES还是直接走db,在某些业务紧急但ES不可用时可以保证业务不受影响。