共识算法ZAB与Zookeeper分布式锁实践
共识算法(Consensus Algorithm)
共识算法即在分布式系统中节点达成共识的算法,提高系统在分布式环境下的容错性。 依据系统对故障组件的容错能力可分为:
- 崩溃容错协议(Crash Fault Tolerant, CFT) : 无恶意行为,如进程崩溃,只要失败的quorum不过半即可正常提供服务
- 拜占庭容错协议(Byzantine Fault Tolerant, BFT): 有恶意行为,只要恶意的quorum不过1/3即可正常提供服务
分布式环境下节点之间是没有一个全局时钟和同频时钟,故在分布式系统中的通信天然是异步的。 而在异步环境下是没有共识算法能够完全保证一致性(极端场景下会出现不一致,通常是不会出现)
In a fully asynchronous message-passing distributed system, in which at least one process may have a crash failure, it has been proven in the famous 1985 FLP impossibility result by Fischer, Lynch and Paterson that a deterministic algorithm for achieving consensus is impossible.
另外网络是否可以未经许可直接加入新节点也是共识算法考虑的一方面, 未经许可即可加入的网络环境会存在女巫攻击(Sybil attack)
分布式系统中,根据共识形成的形式可分为
- Voting-based Consensus Algorithms: Practical Byzantine Fault Tolerance、HotStuff、Paxos、 Raft、 ZAB …
- Proof-based Consensus Algorithms: Proof-of-Work、Proof-of-Stake …
Zookeeper模型与架构
A Distributed Coordination Service for Distributed Applications: ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Zookeeper(后简称zk)定位于分布式环境下的元数据管理,而不是数据库,zk中数据存在内存中,所以不适合存储大量数据。 zk以形如linux文件系统的树形层级结构管理数据,如下图所示: 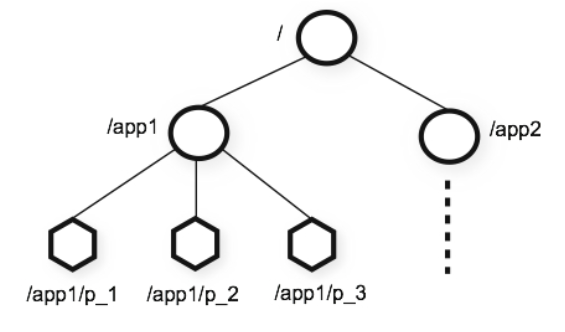
每一个节点称为一个znode除了存放用户数据(一般为1KB以内)还包含变更版本、变更时间、ACL信息等统计数据(Stat Structure):
czxid: The zxid of the change that caused this znode to be created.mzxid: The zxid of the change that last modified this znode.pzxid: The zxid of the change that last modified children of this znode.ctime: The time in milliseconds from epoch when this znode was created.mtime: The time in milliseconds from epoch when this znode was last modified.version: The number of changes to the data of this znode.cversion: The number of changes to the children of this znode.aversion: The number of changes to the ACL of this znode.ephemeralOwner: The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero.dataLength: The length of the data field of this znode.numChildren: The number of children of this znode.
同时znode节点可设置为以下特性:
- ephemeral: 和session生命周期相同
- sequential: 顺序节点,比如创建顺序节点/a/b,则会生成/a/b/0000000001 ,再次创建/a/b,则会生成/a/b/0000000002
- container: 容器节点,用于存放其他节点的节点,子节点无则它也无了,监听container节点需要考虑节点不存在的情况
Zookeeper集群中节点分为三个角色:
- Leader:它负责 发起并维护与各 Follower 及 Observer 间的心跳。所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader。
- Follower:它会响应 Leader 的心跳。Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理,并且负责在 Leader 处理写请求时对请求进行投票。一个 Zookeeper 集群可能同时存在多个 Follower。
- Observer:角色与 Follower 类似,但是无投票权。
为了保证事务的顺序一致性,ZooKeeper 采用了递增的zxid来标识事务,zxid(64bit)由epoch(32bit)+counter(32bit)组成,如果counter溢出会强制重新选主,开启新纪元,如果epoch满了呢?
读操作可以在任意一台zk集群节点中进行,包括watch操作也是,但写操作需要集中转发给Leader节点进行串行化执行保证一致性。 Leader 服务会为每一个 Follower 服务器分配一个单独的队列,然后将事务 Proposal 依次放入队列中,并根据 FIFO(先进先出) 的策略进行消息发送。Follower 服务在接收到 Proposal 后,会将其以事务日志的形式写入本地磁盘中,并在写入成功后反馈给 Leader 一个 Ack 响应。 当 Leader 接收到超过半数 Follower 的 Ack 响应后,就会广播一个 Commit 消息给所有的 Follower 以通知其进行事务提交,之后 Leader 自身也会完成对事务的提交。而每一个 Follower 则在接收到 Commit 消息后,完成事务的提交。 这个流程和二阶段提交很像,只是ZAB没有二阶段的回滚操作。
ZAB(Zookeeper Atomic Broadcast)
Fast Leader Election(FLE)
- myid: 即sid,有cfg配置文件配置,每个节点之间不重复
- logicalclock: 即electionEpoch,选举逻辑时钟
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
public class FastLeaderElection implements Election {
// ...
public Vote lookForLeader() throws InterruptedException {
self.start_fle = Time.currentElapsedTime();
try {
/*
* The votes from the current leader election are stored in recvset. In other words, a vote v is in recvset
* if v.electionEpoch == logicalclock. The current participant uses recvset to deduce on whether a majority
* of participants has voted for it.
*/
// 投票箱, sid : Vote
Map<Long, Vote> recvset = new HashMap<>();
/*
* The votes from previous leader elections, as well as the votes from the current leader election are
* stored in outofelection. Note that notifications in a LOOKING state are not stored in outofelection.
* Only FOLLOWING or LEADING notifications are stored in outofelection. The current participant could use
* outofelection to learn which participant is the leader if it arrives late (i.e., higher logicalclock than
* the electionEpoch of the received notifications) in a leader election.
*/
// 存放上一轮投票和这一轮投票 & (FOLLOWING/LEADING)状态的peer的投票
// 如果有(FOLLOWING/LEADING)的投票来迟了(即已经选出了leader但是当前节点接收ack的notification迟了),
// 可根据outofelection来判断leader是否被quorum ack了,是则跟随该leader
Map<Long, Vote> outofelection = new HashMap<>();
int notTimeout = minNotificationInterval;
synchronized (this) {
// 更新当前electionEpoch
logicalclock.incrementAndGet();
// 更新投票为自己
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 投当前的leader一票,即投自己一票
sendNotifications();
SyncedLearnerTracker voteSet = null;
/*
* Loop in which we exchange notifications until we find a leader
*/
// 循环直到有leader出现
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
// 拉取其他peer的投票
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
if (n == null) { // 没收到peer的投票信息
if (manager.haveDelivered()) { // 上面的notification都发完了
sendNotifications(); // 再发一次
} else {
manager.connectAll(); // 建立连接
}
/*
* 指数退避
*/
notTimeout = Math.min(notTimeout << 1, maxNotificationInterval);
/*
* When a leader failure happens on a master, the backup will be supposed to receive the honour from
* Oracle and become a leader, but the honour is likely to be delay. We do a re-check once timeout happens
*
* The leader election algorithm does not provide the ability of electing a leader from a single instance
* which is in a configuration of 2 instances.
* */
if (self.getQuorumVerifier() instanceof QuorumOracleMaj
&& self.getQuorumVerifier().revalidateVoteset(voteSet, notTimeout != minNotificationInterval)) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
} else if (validVoter(n.sid) && validVoter(n.leader)) { // 收到其他peer的投票
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
// 判断发送投票的peer当前状态
switch (n.state) {
case LOOKING: // 选主中
if (getInitLastLoggedZxid() == -1) {
break;
}
if (n.zxid == -1) {
break;
}
if (n.electionEpoch > logicalclock.get()) { // peer的electionEpoch大于当前节点的electionEpoch
logicalclock.set(n.electionEpoch); // 直接快进到大的epoch,即peer的electionEpoch
recvset.clear(); // 并清空投票箱
// 投票pk
// peer投票和当前节点进行投票pk: peerEpoch -> zxid -> myid(sid)
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
// peer赢了,把当前节点的leader zxid peerEpoch设置为peer的
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
// 当前节点赢了,恢复自己的配置
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 将上面更新后的自己的投票信息广播出去
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
// 如果peer的electionEpoch比当前节点的electionEpoch小,则直接忽略
break;
} else
// electionEpoch相等,进行投票pk: peerEpoch -> zxid -> myid(sid)
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
// pk是peer赢了,跟随peer投票,并广播出去
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
// 将peer的投票放入投票箱
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING: // peer是观察者,不参与投票直接返回
LOG.debug("Notification from observer: {}", n.sid);
break;
/*
* In ZOOKEEPER-3922, we separate the behaviors of FOLLOWING and LEADING.
* To avoid the duplication of codes, we create a method called followingBehavior which was used to
* shared by FOLLOWING and LEADING. This method returns a Vote. When the returned Vote is null, it follows
* the original idea to break switch statement; otherwise, a valid returned Vote indicates, a leader
* is generated.
*
* The reason why we need to separate these behaviors is to make the algorithm runnable for 2-node
* setting. An extra condition for generating leader is needed. Due to the majority rule, only when
* there is a majority in the voteset, a leader will be generated. However, in a configuration of 2 nodes,
* the number to achieve the majority remains 2, which means a recovered node cannot generate a leader which is
* the existed leader. Therefore, we need the Oracle to kick in this situation. In a two-node configuration, the Oracle
* only grants the permission to maintain the progress to one node. The oracle either grants the permission to the
* remained node and makes it a new leader when there is a faulty machine, which is the case to maintain the progress.
* Otherwise, the oracle does not grant the permission to the remained node, which further causes a service down.
*
* In the former case, when a failed server recovers and participate in the leader election, it would not locate a
* new leader because there does not exist a majority in the voteset. It fails on the containAllQuorum() infinitely due to
* two facts. First one is the fact that it does do not have a majority in the voteset. The other fact is the fact that
* the oracle would not give the permission since the oracle already gave the permission to the existed leader, the healthy machine.
* Logically, when the oracle replies with negative, it implies the existed leader which is LEADING notification comes from is a valid leader.
* To threat this negative replies as a permission to generate the leader is the purpose to separate these two behaviors.
*
*
* */
case FOLLOWING: // peer正在following leader
Vote resultFN = receivedFollowingNotification(recvset, outofelection, voteSet, n);
if (resultFN == null) {
break;
} else {
// 成功选主,返回
return resultFN;
}
case LEADING: // peer 是 leader
/*
* In leadingBehavior(), it performs followingBehvior() first. When followingBehavior() returns
* a null pointer, ask Oracle whether to follow this leader.
* */
Vote resultLN = receivedLeadingNotification(recvset, outofelection, voteSet, n);
if (resultLN == null) {
break;
} else {
return resultLN;
}
default:
break;
}
} else {
// 推举的leader或投票的peer不合法,直接忽略
// ...
}
}
return null;
} finally {
// ...
}
}
private Vote receivedFollowingNotification(Map<Long, Vote> recvset, Map<Long, Vote> outofelection,
SyncedLearnerTracker voteSet, Notification n) {
/*
* Consider all notifications from the same epoch
* together.
*/
if (n.electionEpoch == logicalclock.get()) { // 同一轮投票
// 若对方选票中的electionEpoch等于当前的logicalclock,
// 说明选举结果已经出来了,将它们放入recvset。
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
voteSet = getVoteTracker(recvset, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
// 判断quorum是否满足选主条件
if (voteSet.hasAllQuorums() &&
// 判断推举的leader已经被quorum ack了,避免leader挂了导致集群一直在选举中
checkLeader(recvset, n.leader, n.electionEpoch)) {
// leader是自己,将自己设置为LEADING,否则是FOLLOWING(或OBSERVING)
setPeerState(n.leader, voteSet);
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
// 清空消费投票的queue
leaveInstance(endVote);
return endVote;
}
}
// 到这里是
// peer的electionEpoch和logicalclock不一致
// 因为peer是FOLLOWING,所以在它的electionEpoch里已经选主成功了
/*
* 在跟随peer选出的leader前,校验这个leader合法不合法
* Before joining an established ensemble, verify that
* a majority are following the same leader.
*
* Note that the outofelection map also stores votes from the current leader election.
* See ZOOKEEPER-1732 for more information.
*/
outofelection.put(n.sid, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
voteSet = getVoteTracker(outofelection, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
if (voteSet.hasAllQuorums() && checkLeader(outofelection, n.leader, n.electionEpoch)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
setPeerState(n.leader, voteSet);
}
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
return null;
}
private Vote receivedLeadingNotification(Map<Long, Vote> recvset, Map<Long, Vote> outofelection, SyncedLearnerTracker voteSet, Notification n) {
/*
* 在两个节点的集群中(leader+follower),如果follower挂了,recovery之后,因为投票无法过半(follower会首先投自己一票),会找不到leader
* In a two-node configuration, a recovery nodes cannot locate a leader because of the lack of the majority in the voteset.
* Therefore, it is the time for Oracle to take place as a tight breaker.
* */
Vote result = receivedFollowingNotification(recvset, outofelection, voteSet, n);
if (result == null) {
/*
* Ask Oracle to see if it is okay to follow this leader.
* We don't need the CheckLeader() because itself cannot be a leader candidate
* */
// needOracle,当集群无follower & 集群voter==2 时,
if (self.getQuorumVerifier().getNeedOracle()
// 且cfg配置中key=oraclePath的文件(默认没有,askOracle默认false)中的值 != '1' 时会走到if里
// 这里可参考官网 https://zookeeper.apache.org/doc/current/zookeeperOracleQuorums.html
&& !self.getQuorumVerifier().askOracle()) {
LOG.info("Oracle indicates to follow");
setPeerState(n.leader, voteSet);
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
} else {
LOG.info("Oracle indicates not to follow");
return null;
}
} else {
return result;
}
}
// ...
}
Recovery Phase
Broadcast Phase
Packet : a sequence of bytes sent through a FIFO channel
Proposal : a unit of agreement. Proposals are agreed upon by exchanging packets with a quorum of ZooKeeper servers. Most proposals contain messages, however the NEW_LEADER proposal is an example of a proposal that does not correspond to a message.
Message : a sequence of bytes to be atomically broadcast to all ZooKeeper servers. A message put into a proposal and agreed upon before it is delivered.
The zxid has two parts: the epoch and a counter.
ZooKeeper messaging consists of two phases:
- Leader activation : In this phase a leader establishes the correct state of the system and gets ready to start making proposals.
- Active messaging : In this phase a leader accepts messages to propose and coordinates message delivery.
A leader becomes active only when a quorum of followers (The leader counts as a follower as well. You can always vote for yourself ) has synced up with the leader, they have the same state.
two leader election algorithms in ZooKeeper:
- LeaderElection
- FastLeaderElection
ZooKeeper messaging doesn’t care about the exact method of electing a leader has long as the following holds:
- The leader has seen the highest zxid of all the followers.
- A quorum of servers have committed to following the leader.
- Consensus Algorithms in Distributed Systems
- FLP Impossibility Result
- zookeeperInternals
- 详解分布式协调服务 ZooKeeper,再也不怕面试问这个了
- Lecture 8: Zookeeper
- ZooKeeper: Wait-free coordination for Internet-scale systems
- diff_acceptepoch_currentepoch
- Zookeeper(FastLeaderElection选主流程详解)
- zookeeper-framwork-design-message-processor-leader