分布式缓存实践
分布式缓存实践
分布式缓存主要用于查询场景,缓解DB压力,针对不同的一致性要求分为两种缓存场景:
- 最终一致性分布式缓存
- 强一致分布式缓存
CAP中的C表示的是多副本一致性 ACID中的C表示的是动作一致性,比如A给B打钱
最终一致性分布式缓存
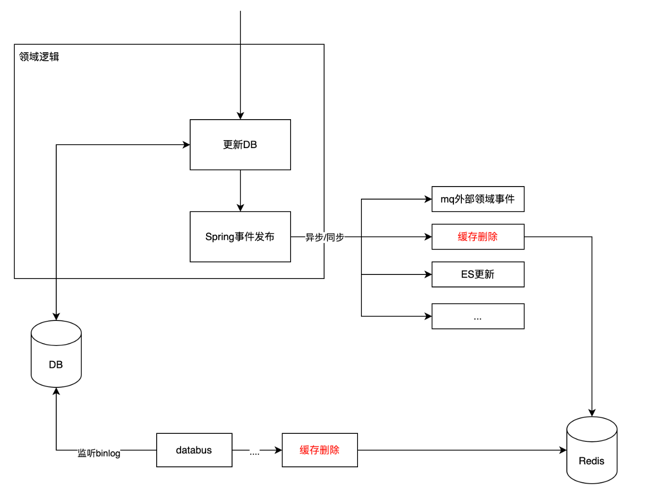
最终一致性对一致性要求不高,可以采用异步更新的方式避免业务系统阻塞。 采用旁路缓存模式,先去缓存获取数据,存在则直接返回,不存在去读DB,然后根据DB值设置缓存;同时,更新DB数据后需要主动删除缓存,避免脏数据。 更新DB数据后如何触发缓存删除动作呢?一般有两种方式:
- domain层发送领域事件触发
- 监听数据库数据变化(如binlog)触发
(这里使用直接更新方式,也可以通过mq异步更新缓存)
当然,两种方式可以同时存在:
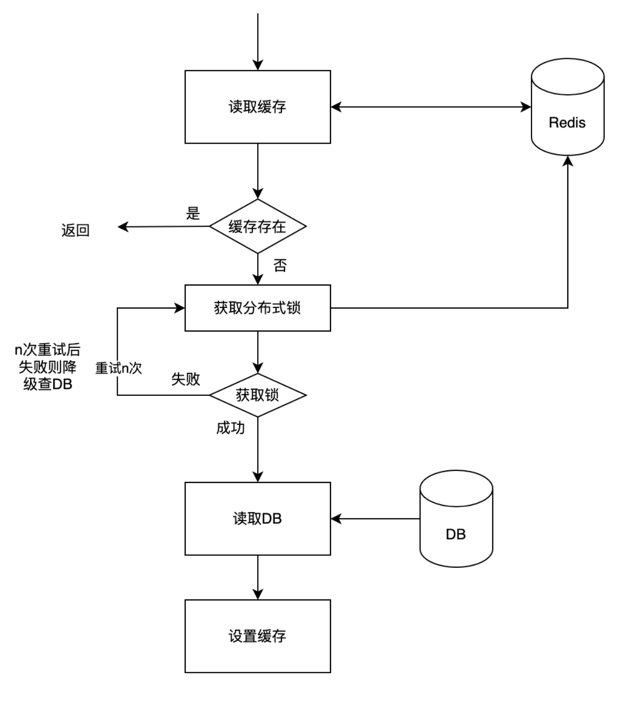
缓存删除后在查缓存不存在,则会去DB取数据,而当某一时刻查询并发大时,则会导致缓存穿透,为避免该问题,可在读取DB数据设置缓存前获取分布式锁:
在该最终一致性场景下,如第一张图所示,更新DB和缓存删除操作并非原子操作,高查询并发或更新时会存在2种缓存脏数据的情况:
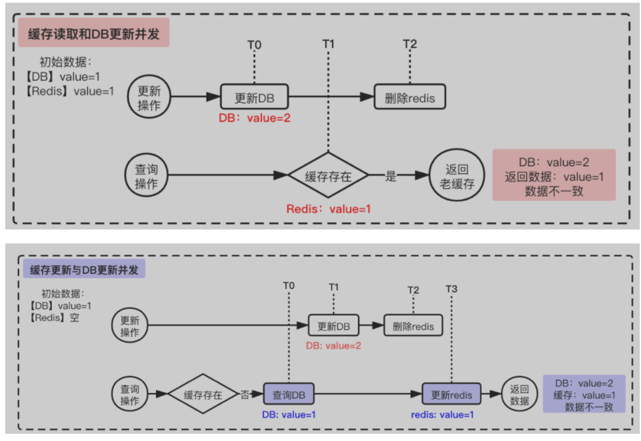
那么在强一致场景下,这种脏数据如何避免呢?
强一致分布式缓存
加锁
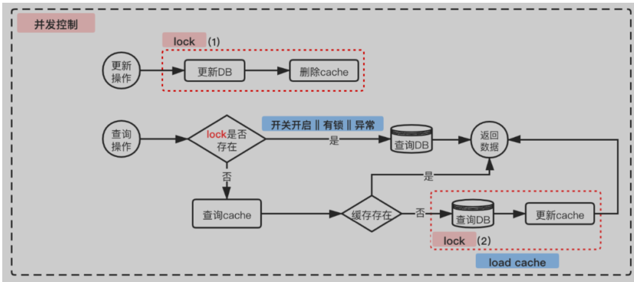
在强一致场景下,需要舍弃性能保证(锁的粒度较大)来保证数据一致性,两处lock指向同一个分布式锁
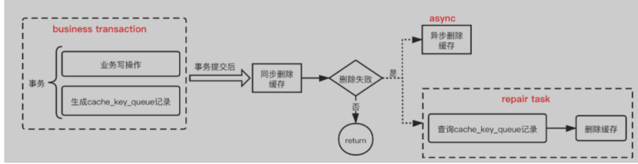
缓存删除失败怎么办
缓存失败的原因可能是缓存服务不可用、网络波动,其中网络波动可以通过重试补偿,而服务不可用时要及时告警且人员第一时间介入,同时,增加降级开关和熔断机制保证业务的可用性。这里只针对网络波动提供通用解决方案: 首先,缓存key需要添加超时时间,避免key长期存在,当然针对某些热点key可设置永不过期,网络波动场景下(或服务不可用重启后),数据库更新后的缓存删除动作必须保证成功,通过重试机制来保证“必须”,可以添加一个本地重试表(类似本地消息表)来记录缓存删除状态,后续可通过定时任务异步执行重试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
create table gaotu_express.express_retry
(
id bigint auto_increment comment '自增主键' primary key,
number bigint not null comment '雪花id',
type tinyint not null comment 'biz_number对应类型 0-发货单,1-订单',
key bigint not null comment '缓存key',
retry_status tinyint default 0 not null comment '重试状态,0-待重试,1-重试成功',
retry_times tinyint default 0 not null comment '重试次数',
ext_info text null comment 'json格式额外信息',
next_retry_time datetime not null comment '下一次执行重试时间',
create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',
update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '修改时间',
constraint unq_number unique (number)
)
comment '物流重试表';
create index idx_update_time_status
on gaotu_express.express_retry (next_retry_time, retry_status, type);
This post is licensed under CC BY 4.0 by the author.