数据库实例迁移实践
背景
随着业务发展,数据库实例磁盘逐渐升高,告警频繁,且后续可能会对DDL产生影响(尤其是借助ghost等工具执行的DDL)。
该实例有多个库,则需要迁移其中的一个或几个单库到其他实例,为什么不做分库分表?一是没必要,数据增长没有那么快;二是改动大,影响范围大。 故采用库实例迁移的方式来缓解磁盘压力。
依赖梳理
库本身的迁移好办,麻烦的是库下游的依赖迁移,比如DTS、大数据等依赖。所以在迁移前需要对待迁移库的流量做全面梳理,梳理完好库读写来源后再确立方案。
一个库的上下游依赖关系可以大致表示为:
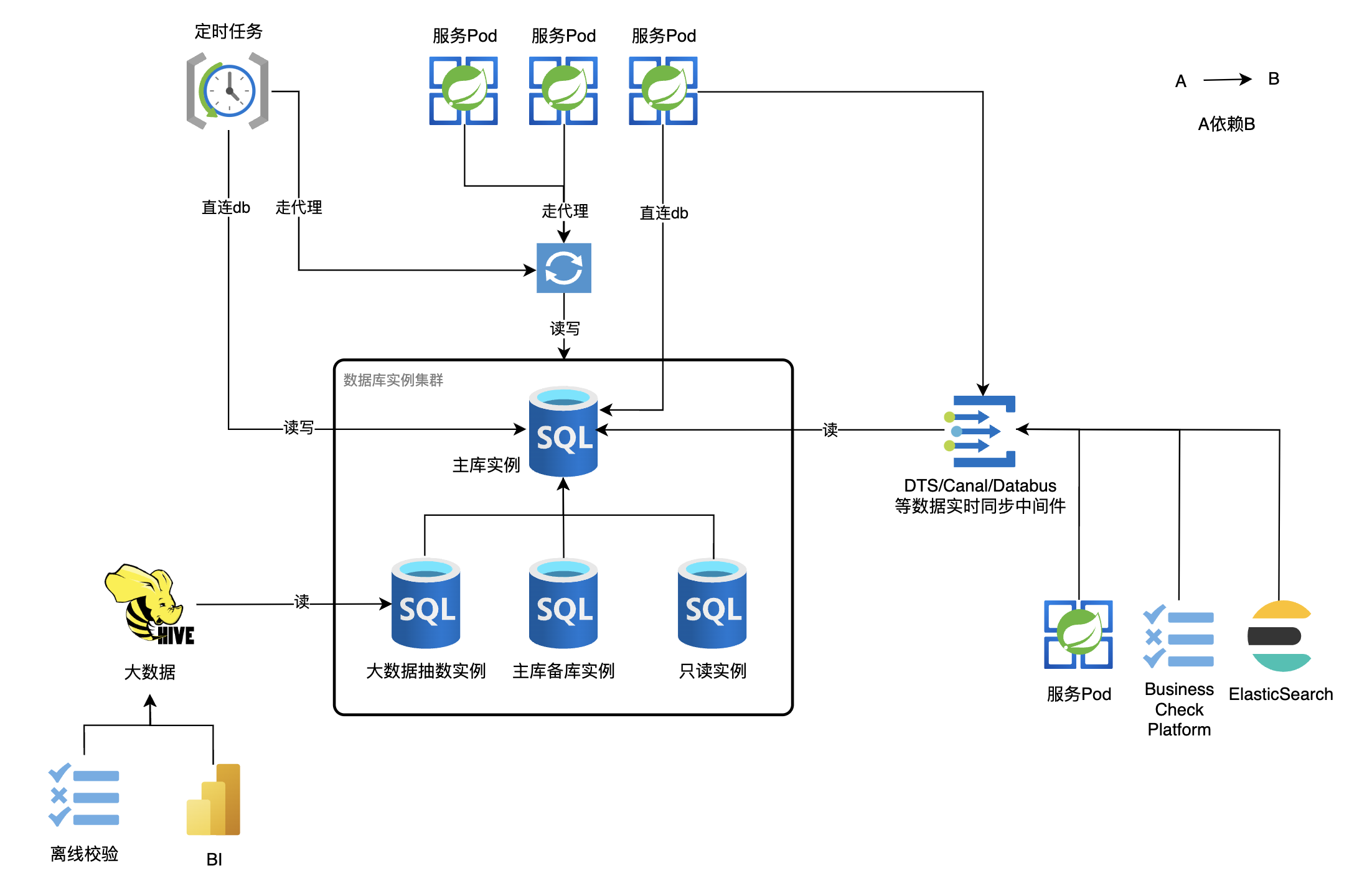
一个库通常分布在多个实例,其中主库实例支持读写请求,下面的从库只接受读请求,如大数据抽数实例,为了不让大数据抽数影响业务数据读写,故抽出了一个实例。
服务读写库的方式通过一层数据库代理中间件,好处一是可以控制数据库连接,避免连接资源耗尽;二是可以使用唯一标识代替数据库用户名密码访问,更加安全; 三是在数据库实例切换时,可以在该代理修改唯一标识指向的实例达到快速切换的目的。 如果数据库使用用户名密码直连的方式访问,则迁移前梳理读写流量来源会更加麻烦,最好将服务读写请求收口到一处,做到单点变更。 此外,可能会有定时任务会在每次运行时新建数据库连接(比如Xxl-Job的glue模式),这个也要在前期梳理好,避免后续db实例切换时遗漏造成数据错乱。
为了实时监听数据变更,会有DTS等数据订阅中间件(实时同步),下游通过订阅该DTS来监听数据变更。
方案步骤
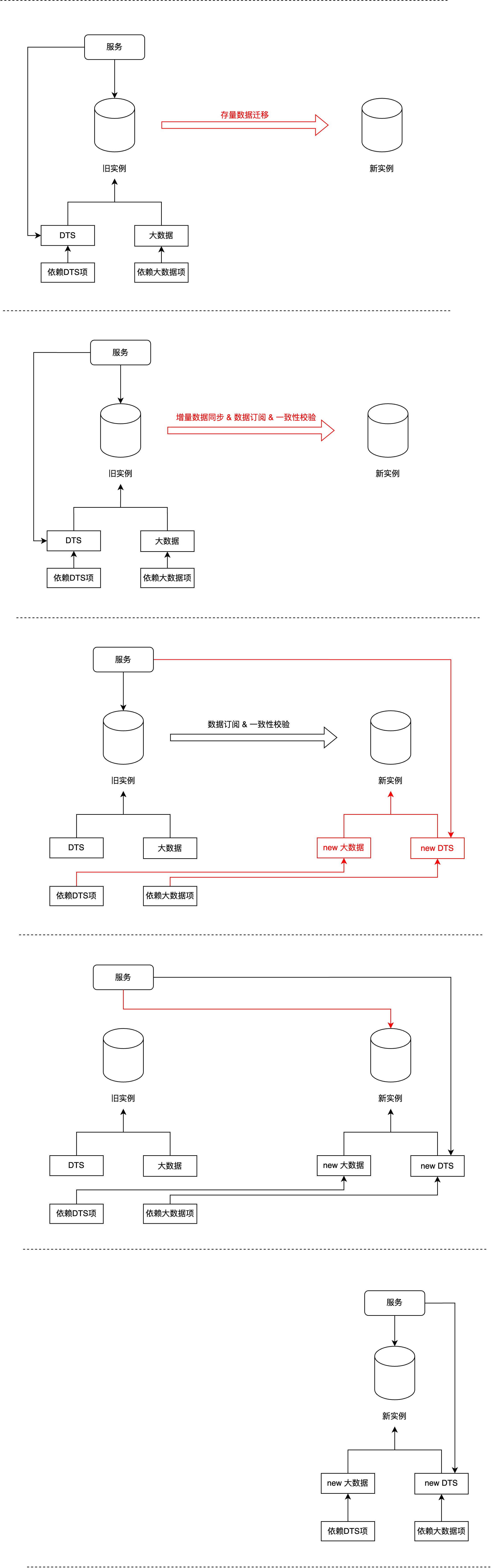
迁移可分为5个步骤:
- 存量数据迁移:存量数据批量迁移;
- 增量数据同步,新库订阅老库并开启一致性校验:同步在存量迁移期间变更的数据(update_time >= 存量迁移开始时间),之后新库订阅老库变更;
- 库下游依赖切换/迁移:首先切换或迁移下游依赖,如果下游依赖支持平滑切换数据库实例,则直接切换即可,否则得新建一套班子依赖新实例;
- 服务读写切换:服务读写从旧库切换到新库;
- 善后工作:旧库依赖清理,旧库清理等;
其中1,2两步中,有些公司已经有了成熟的工具,如果是手动开发代码来迁移,可以再此基础上增加灰度策略,本案例只讨论全量切场景,且数据库表均为平迁。
以上3,4两步的切换操作需要在业务低峰期操作,尽量减小切换带来的影响,切换后需要立即验证数据并稳定运行一段时间后执行下一步。
迁移前开发
拉上相关人员建群,群里同步信息,避免遗漏。
同时,在迁移前需要评估是否需要进行相关代码改造,便于后续平滑切换。
数据库连接统一配置 & 配置化连接
数据库连接的配置需要收口到可控的一处或几处: 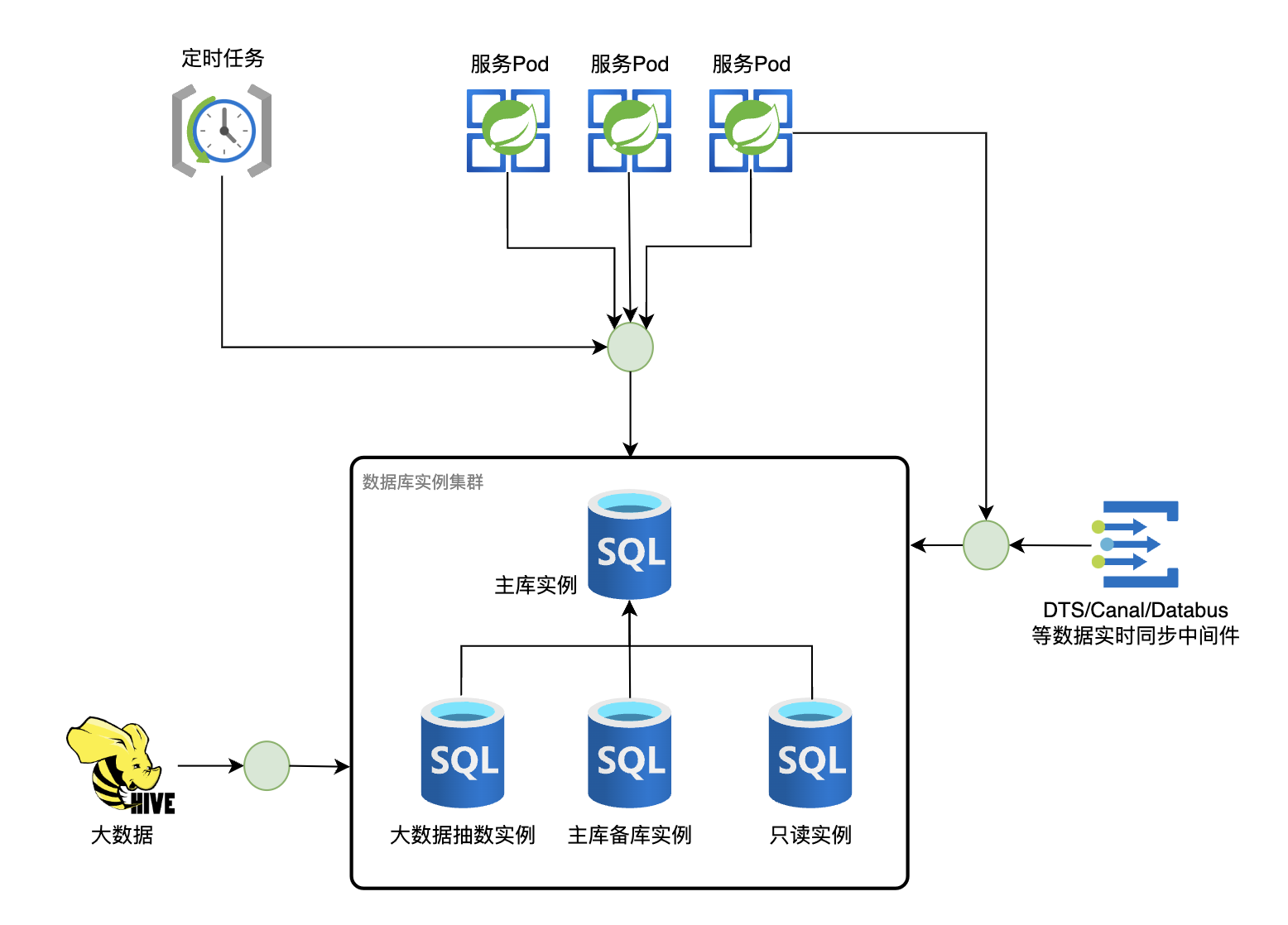
且针对每一处收口,需要配置化连接,即配置变更立即变更数据库连接到新实例。 这种可以在数据库代理层做,没有也可以通过改造服务代码,通过监听配置中心数据库配置来变更数据库连接。
数据库停写开关 & DTS订阅配置化
在DTS切换时过程中,可能会存在重复消费的情况 。 订阅DTS的下游消费可能并不幂等,如果可以说服下游让其进行幂等改造最好,不行的话,则可以在针对DTS订阅的库表加上停写开关,在业务低峰期切换前,打开停写开关,等待DTS消费量归零后,执行切换,然后关闭停写开关。
DTS下游订阅,通常通过@PostConstruct注解实现注册消费者,该方式无法在配置变更后主动变更消费新DTS,只能重启。这样切换时间加长,需要仔细评估是否可行。