Caffeine Cache under the hood
Caffeine is a high performance Java caching library providing a near optimal hit rate.
- 自动加载value, 支持异步加载
- 基于size的eviction:frequency and recency
- 基于时间的过期策略:last access or last write
- 异步更新value
- key支持weak reference
- value支持weak reference和soft reference
- 淘汰(或移除)通知
- 缓存获取数据统计
Caffeine的性能benchmark可参考Caffeine Benchmarks, 可以看到Caffeine在不同读写比的情况下, 吞吐量比Guava Cache和Jdk内置的HashMap都有较大提升。 接下来了解下Caffeine的使用和实现原理。
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// manual cache,Cache-Aside模式
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofHours(1))
.build();
// null表示不存在key
@Nullable String val = cache.getIfPresent("hello");
if (val == null) {
cache.put("hello", "world");
}
// key不存在则走后面的loading function
String val2 = cache.get("hello", key -> "world");
// loading cache,Read-Through模式
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.expireAfterAccess(Duration.ofMinutes(10))
.maximumSize(2000)
.build(new CacheLoader<String, String>() {
@Override
public @Nullable String load(@NonNull String s) throws Exception {
// your loading logic
return "";
}
});
// 不存在会自动loading
String val3 = loadingCache.get("hello");
接口设计
CacheCache按不同维度划分:
- kv是否有限:Bounded or Unbounded,判断参见方法
com.github.benmanes.caffeine.cache.Caffeine#isBounded,大部分场景都使用BoundedCache - 是否自动loading: ManualCache和LoadingCache
- 是否异步: Cache和AsyncCache
对应接口UML如下(实现类只画出了BoundedCache),其接口和类均位于com.github.benmanes.caffeine.cache包下:
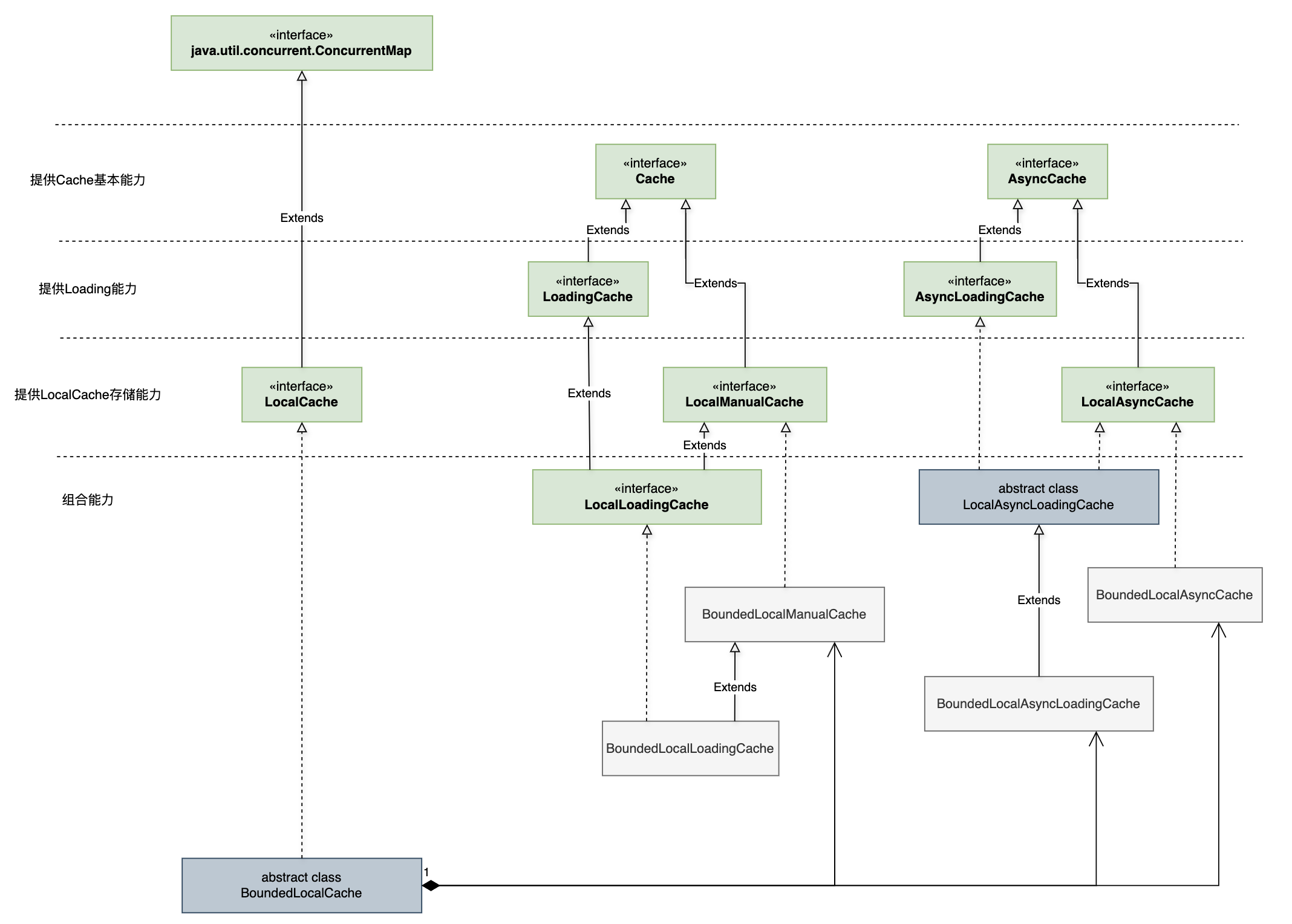
可以看到,核心的kv存储是放在了LocalCache接口(本质是一个ConcurrentMap)下,而其他的Loading和Async接口在存储基础上附加了自动加载value和异步加载的能力,以同步接口为例,接口能力如下:
Cache: 提供缓存基础能力,包含设置、读取、失效、获取缓存统计数据等功能;LoadingCache: 提供自动加载能力,在Cache基础上新增不存在则loading value的读取以及refresh方法;LocalCache: 提供核心存储能力,线程安全和原子能力保证,继承自java.util.concurrent.ConcurrentMap;LocalManualCache: 基于LocalCache做存储的非自动Loading Cache;LocalLoadingCache: 继承自LocalManualCache,新增Loading功能。
关于以上接口的一个关键抽象实现类BoundedLocalCache,其作用解释如下:
This class performs a best-effort bounding of a ConcurrentHashMap using a page-replacement algorithm to determine which entries to evict when the capacity is exceeded.
TinyLFU & W-TinyLFU
在看BoundedLocalCache类前先来了解下TinyLFU & W-TinyLFU算法, 算法出自论文:TinyLFU: A Highly Efficient Cache Admission Policy
- admission policy:控制一个元素是否能进入缓存
- eviction policy:当缓存满了时选择哪一个元素剔除缓存
论文中提出的TinyLFU指的是admission policy, TinyLFU可以和 LRU 、SLRU 的eviction policy组合。
比如 论文中使用W-TinyLFU + LRU + SLRU的组合进行实验:
Window Tiny LFU (W-TinyLFU) … consists of two cache areas. The main cache employs the SLRU eviction policy and TinyLFU admission policy while the window cache employs an LRU eviction policy without any admission policy.
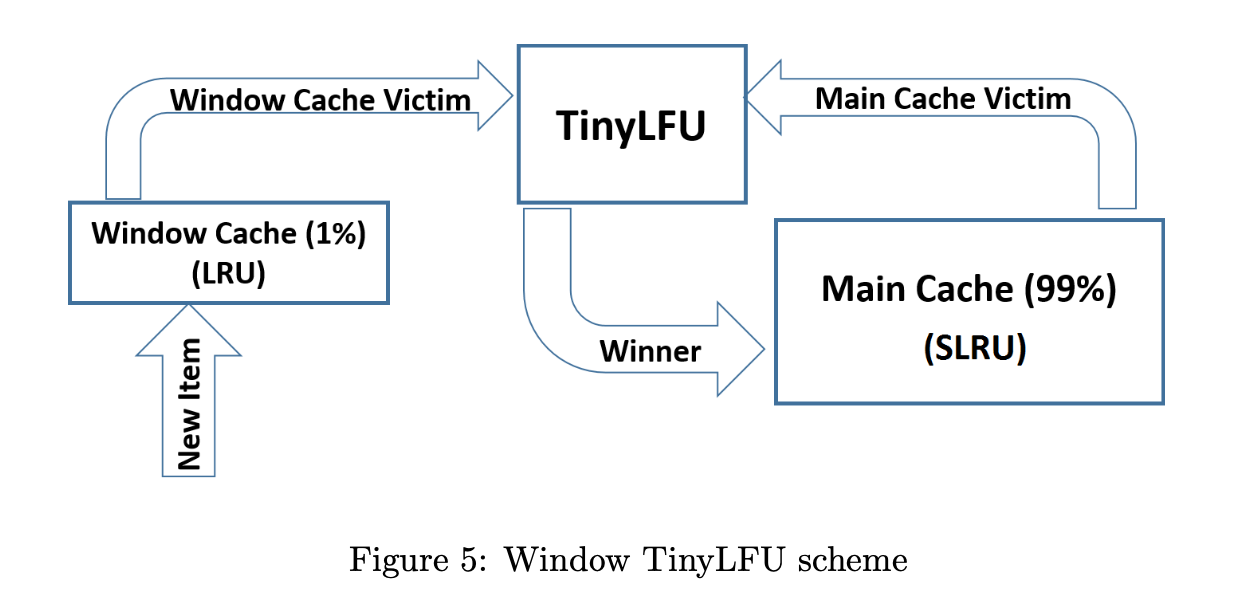
可以看到 W-TinyLFU 的main cache area 使用 TinyLFU 作为 admission policy。
TinyLFU 在 LFU的基础上 加了Tiny,而Tiny体现在counter计数(和frequency正相关) 的记录上。 通常大部分缓存的元素访问频率都会很小,如果使用integer来记录counter计数,会导致空间浪费,因此 TinyLFU 借助 approximate counting scheme 来记录counter计数,其原理和bloom filter类似,而 schema的具体实现有:
Counting Bloom FilterCM-Sketch: Caffeine中使用该实现,参见类com.github.benmanes.caffeine.cache.FrequencySketch,论文可参考:An Improved Data Stream Summary: The Count-Min Sketch and its Applications
Caffeine中的CM-Sketch使用4bit记录counter次数,最大只能到15, 并使用long[]类型存储,一个元素可存储16个计数器,long[]即相当于论文中的二维数组。
此外还增加了一个DoorKeeper即一个Bloom Filter来优先存储counter计数为1的元素,大于1的才会进入CM-Sketch结构中。
此外,TinyLFU利用Freshness Mechanism保证TinyLFU计数器记录的次数不会无限制扩大:
Every time we add an item to the approximation sketch, we increment a counter. Once this counter reaches the sample size (W), we divide it and all other counters in the approximation sketch by 2.
对应的可以在FrequencySketch类的increment方法中找到reset方法的调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// This class maintains a 4-bit CountMinSketch.
// The maximum frequency of an element is limited to 15 (4-bits)
// and an aging process periodically halves the popularity of all elements.
final class FrequencySketch<E> {
...
int sampleSize;
int size;
public void ensureCapacity(@NonNegative long maximumSize) {
...
sampleSize = (maximumSize == 0) ? 10 : (10 * maximum);
if (sampleSize <= 0) {
sampleSize = Integer.MAX_VALUE;
}
size = 0;
}
// 计数器次数小于15时才会增加计数器
public void increment(@NonNull E e) {
...
boolean added = ...
if (added && (++size == sampleSize)) {
reset();
}
}
...
}
BoundedLocalCache之DrainStatus
1
final ConcurrentHashMap<Object, Node<K, V>> data;
数据最终都会被存储在该字段,其中的key的Object可能是强引用或弱引用,统一通过final NodeFactory<K, V> nodeFactory字段的 nodeFactory.newLookupKey(key)方式获取:
- cache定义key为强引用时:
newLookupKey返回的即为用户输入key - cache定义key为弱引用时:
newLookupKey返回LookupKeyReference
但page replacement policy(即admission policy + evict policy)的执行并不根据data这个字段判断,而是通过另外两个字段:
MpscGrowableArrayQueue<Runnable> writeBuffer: 每次afterWrite会同时写入Buffer<Node<K, V>> readBuffer: 每次afterRead会同时写入
这样page replacement policy不会阻塞主线程操作。
The page replacement algorithms are kept eventually consistent with the map
可以看到buffers中内容和data的内容是最终一致的,即data中即使存在Node也不一定能用(可能已经过期/待被evict)。
只有当data中和page replacement algorithms都有该Node时,才算cache中包含该Node。
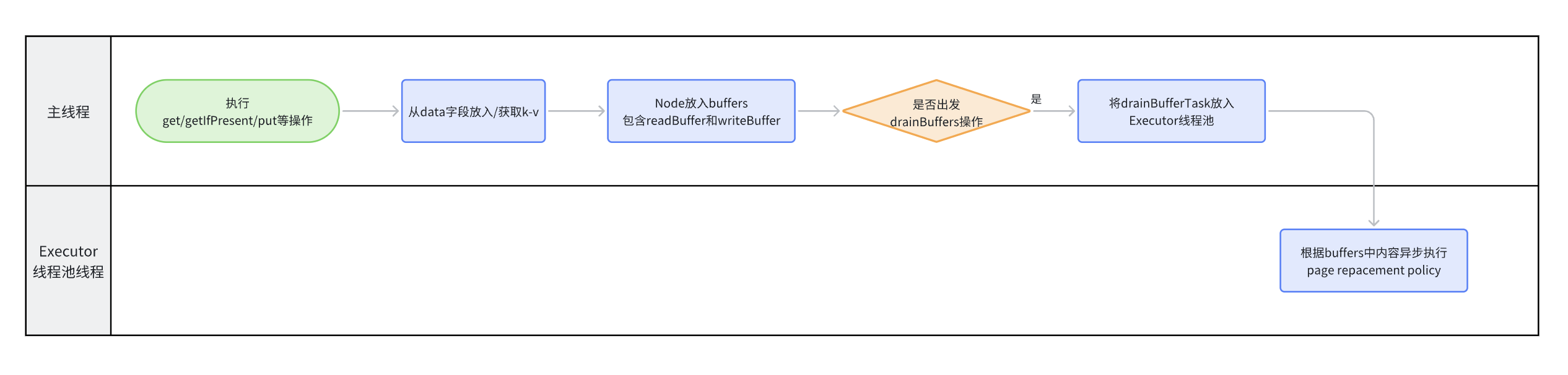
那么何时触发 page replacement algorithms(即drain buffers)呢?
These buffers are drained(只是放入Executor线程池,异步drain,通过加锁和cas操作完成) at the first opportunity after a write or when a read buffer is full
大致调用如下: 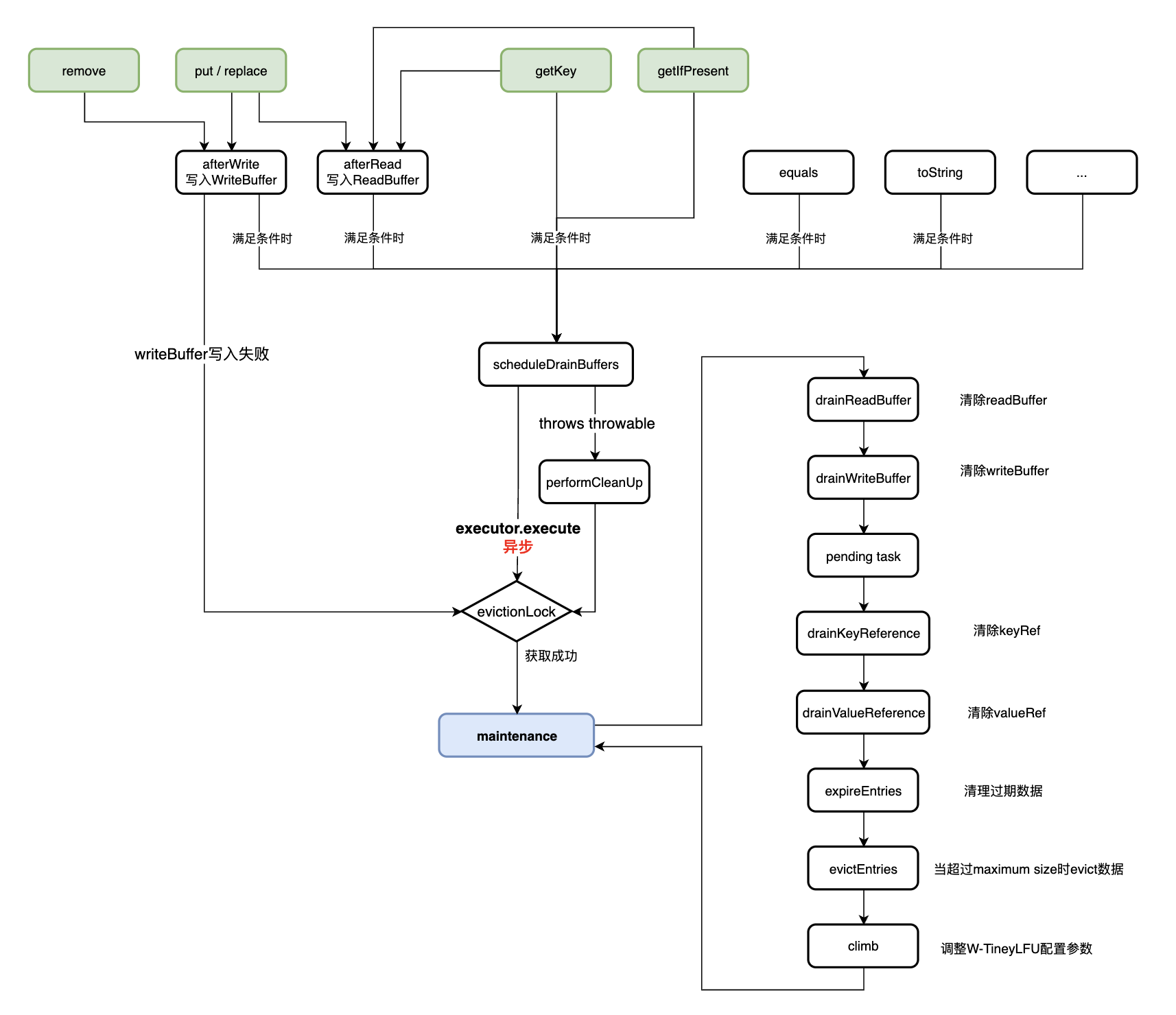
既然是多线程,肯定有并发控制,Caffeine通过java.util.concurrent.locks.ReentrantLock以及CAS操作Drain的状态机来控制并发。 每次执行maintenance方法时都会先获取ReentrantLock;此外,有些场景可以直接cas设置状态就不需要加锁了, Drain的状态共有4种: IDLE , REQUIRED , PROCESSING_TO_IDLE , PROCESSING_TO_REQUIRED. Drain的状态统一由BoundedLocalCache的父抽象类DrainStatusRef管理, 由于涉及多线程修改,该抽象类继承了PadDrainStatus来防止伪共享(false sharing)。
抽象类DrainStatusRef中使用一个volatile int drainStatus字段来记录状态,volatile保证字段变更时的内存可见性。
但DrainStatusRef并不直接操作该字段, 而是通过抽象类DrainStatusRef的static final VarHandle DRAIN_STATUS字段来操作drainStatus,其类型为java.lang.invoke.VarHandle。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
abstract static class DrainStatusRef extends PadDrainStatus {
static final VarHandle DRAIN_STATUS;
...
/** The draining status of the buffers. */
volatile int drainStatus = ...;
int drainStatusOpaque() {
return (int) DRAIN_STATUS.getOpaque(this);
}
int drainStatusAcquire() {
return (int) DRAIN_STATUS.getAcquire(this);
}
void setDrainStatusOpaque(int drainStatus) {
DRAIN_STATUS.setOpaque(this, drainStatus);
}
void setDrainStatusRelease(int drainStatus) {
DRAIN_STATUS.setRelease(this, drainStatus);
}
boolean casDrainStatus(int expect, int update) {
return DRAIN_STATUS.compareAndSet(this, expect, update);
}
static {
try {
DRAIN_STATUS = MethodHandles.lookup()
.findVarHandle(DrainStatusRef.class, "drainStatus", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
}
为什么通过java.lang.invoke.VarHandle的变量句柄来操作呢?为了保证多线程修改状态时的状态字段内存可见性。
VarHandle支持5中操作类型(参见VarHandle内部枚举AccessType):
- GET
- SET
- COMPARE_AND_SET
- COMPARE_AND_EXCHANGE
- GET_AND_UPDATE
Access modes control atomicity and consistency properties.
为了保证变量操作的原子性和内存一致性,又有以下5种AccessMode根据严格程度从弱到强为:
- plain: 即普通的get/set, 存在指令重排,不保证内存可见性
- opaque: 当前线程不存在指令重排(不通过内存屏障实现),但不保证其他线程
- acquire/release: getAcquire-后续的load & store不会重排序到当前操作前 ; setRelease-前面的load & store 不会重排序到当前操作后
- volatile: 和volatile关键字效果一样
关于volatile关键字的重排序规则如下: 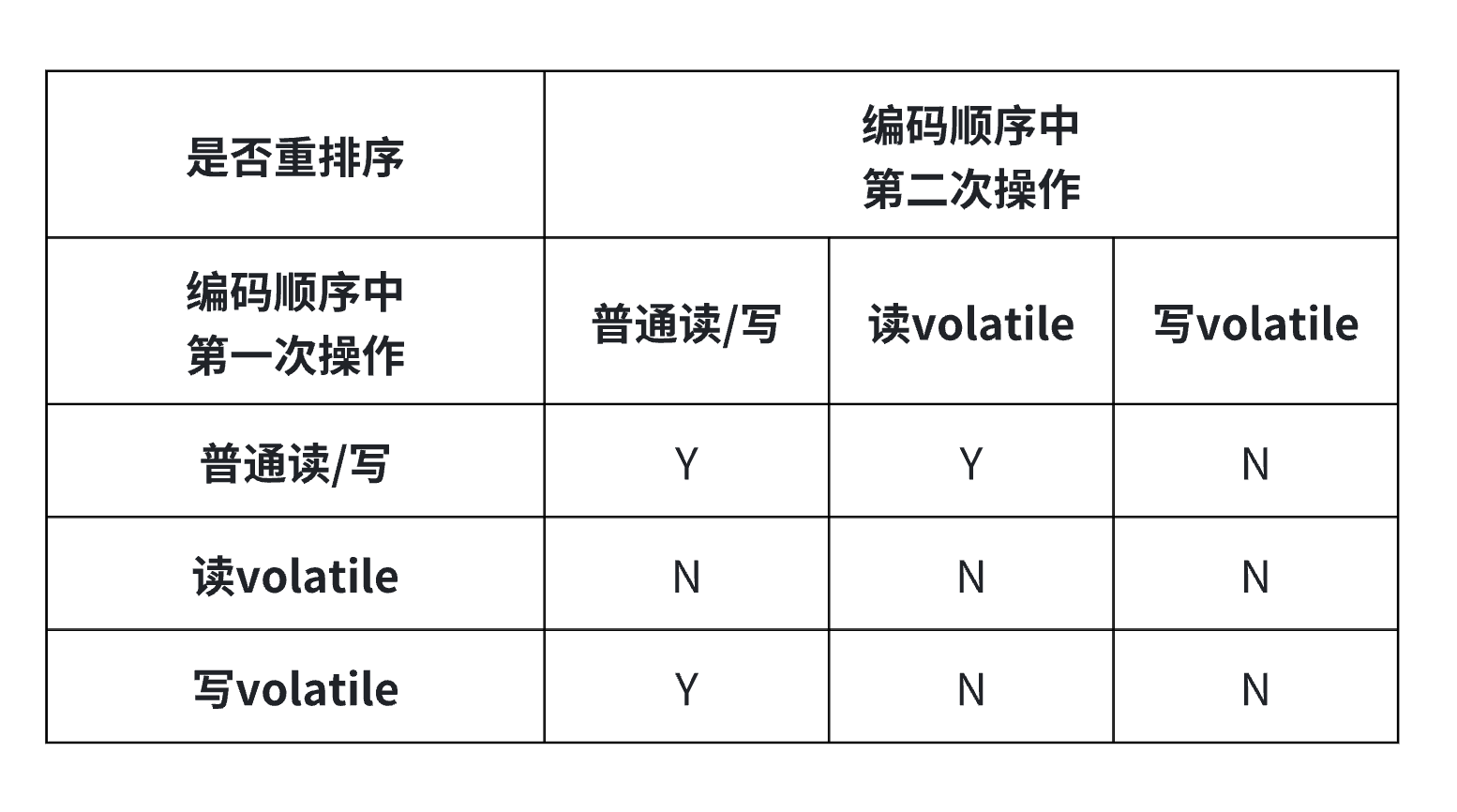
需要指出的是,只有单线程情况下不影响执行结果时才有可能发生指令重排序, 而以上需要防止重排序产生的内存可见性问题,是基于多核处理器并发执行的场景。
说回drainStatus,drainStatus有以下几个:
- IDLE(0): 不需要执行drainBuffers
- REQUIRED(1): 需要执行drainBuffers
- PROCESSING_TO_IDLE(2): drainBuffers异步任务提交前设置,下一个状态会是IDLE(实际不一定,也会流转到PROCESSING_TO_REQUIRED)
- PROCESSING_TO_REQUIRED(3): drainBuffers正在执行但此时又有drain任务提交,则后续还要继续触发drain,下一个状态会是REQUIRED
其状态机如下图: 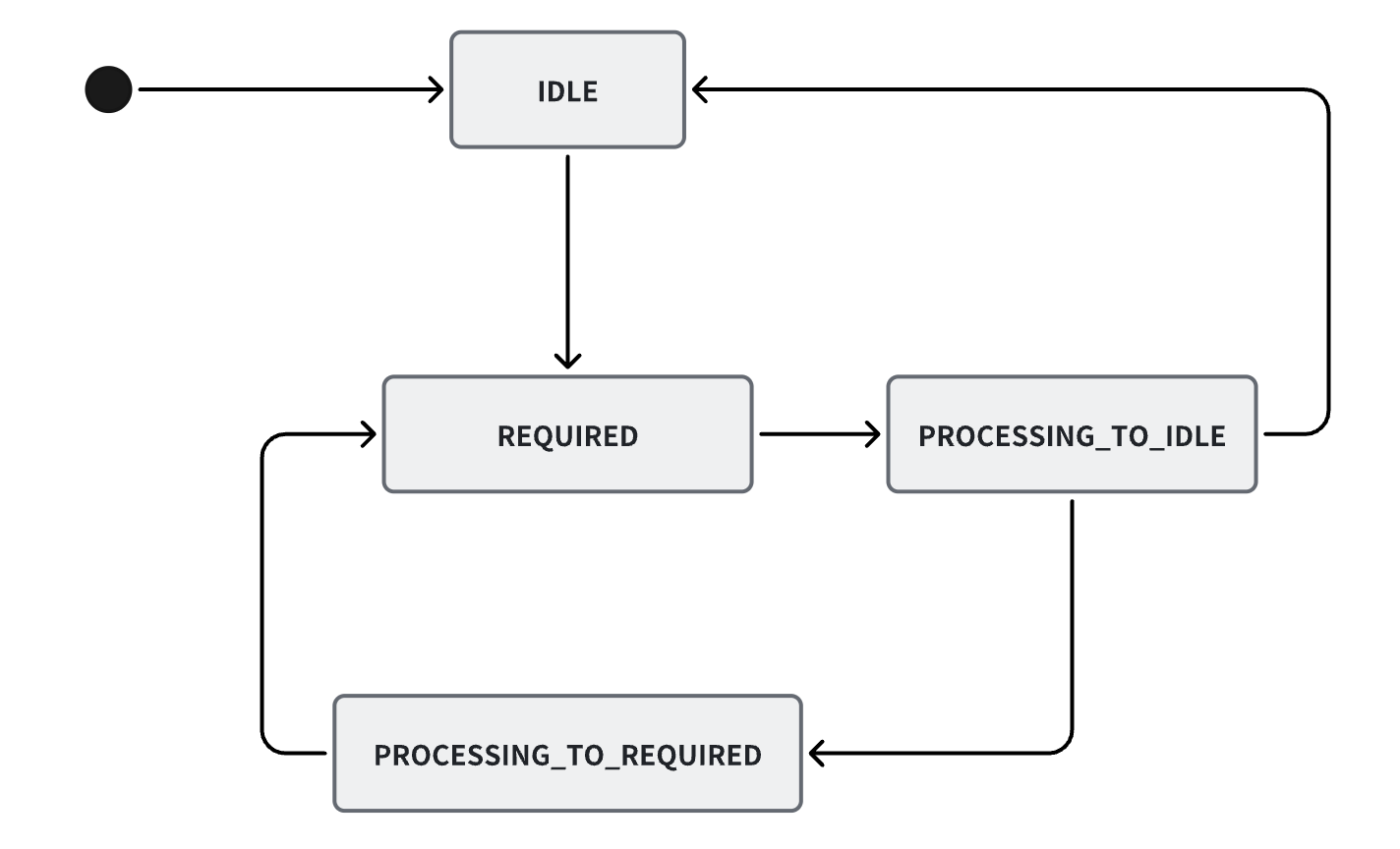
如前文所述,每次write(包含writeBuffer满了的情况)或readBuffer满了就会触发drainBuffers操作,那么代码中这两处是如何流转drainStatus呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
// 当buffers满了触发
void scheduleDrainBuffers() {
// 已经有触发后续drain了即为PROCESSING_TO_REQUIRED,则直接返回
if (drainStatusOpaque() >= PROCESSING_TO_IDLE) {
return;
}
// 加锁
if (evictionLock.tryLock()) {
try {
int drainStatus = drainStatusOpaque();
// 二次判断:已经有触发后续drain了即为PROCESSING_TO_REQUIRED,则直接返回
if (drainStatus >= PROCESSING_TO_IDLE) {
return;
}
// drain提上日程
setDrainStatusRelease(PROCESSING_TO_IDLE);
// 提交task
executor.execute(drainBuffersTask);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown when submitting maintenance task", t);
maintenance(/* ignored */ null);
} finally {
evictionLock.unlock();
}
}
}
// write后插入writeBuffer成功后执行
void scheduleAfterWrite() {
@Var int drainStatus = drainStatusOpaque();
for (;;) {
switch (drainStatus) {
case IDLE:
// 设置为需要drain
casDrainStatus(IDLE, REQUIRED);
// 提交drain task
scheduleDrainBuffers();
return;
case REQUIRED:
// 提交drain task
scheduleDrainBuffers();
return;
case PROCESSING_TO_IDLE:
// 到这里说明前面有其他线程提交了drain task
// 则这里cas设置为PROCESSING_TO_REQUIRED
if (casDrainStatus(PROCESSING_TO_IDLE, PROCESSING_TO_REQUIRED)) {
return;
}
// cas失败说明status不是PROCESSING_TO_IDLE,那就更新当前局部变量的drainStatus
drainStatus = drainStatusAcquire();
continue;
case PROCESSING_TO_REQUIRED:
return;
default:
throw new IllegalStateException("Invalid drain status: " + drainStatus);
}
}
}
// 加完锁执行drainBuffers等操作
@GuardedBy("evictionLock")
void maintenance(@Nullable Runnable task) {
setDrainStatusRelease(PROCESSING_TO_IDLE);
try {
...
} finally {
// 当前状态不是 PROCESSING_TO_IDLE ,则一定为 PROCESSING_TO_REQUIRED,说明还要drain一次,则状态变为REQUIRED
if ((drainStatusOpaque() != PROCESSING_TO_IDLE)
// cas设置为IDLE,失败了也变成REQUIRED(可能前面判断和这次判断中间有其他线程改为PROCESSING_TO_REQUIRED了)
|| !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {
setDrainStatusOpaque(REQUIRED);
}
}
}
看看上面的多线程任务提交状态流转的考量,在我们的业务应用层面也可以借鉴,所以说读源码才是王道。
BoundedBuffer 与 MpscGrowableArrayQueue
multiple-producer / single-consumer
这里multiple和single指的是并发数量
- BoundedBuffer: Caffeine中readBuffer字段实现 , A striped, non-blocking, bounded buffer.
- MpscGrowableArrayQueue: Caffeine中writeBuffer字段实现, An MPSC array queue which starts at initialCapacity and grows to maxCapacity in linked chunks of the initial size. The queue grows only when the current buffer is full and elements are not copied on resize, instead a link to the new buffer is stored in the old buffer for the consumer to follow.
BoundedBuffer
BoundedBuffer继承自StripedBuffer,其中stripe表示条、带的意思,StripedBuffer即做了分段处理, 增加写入并发度。StripedBuffer类似一个门面,其中的volatile Buffer<E> @Nullable[] table; 实际存放数据,而这里的Buffer接口实现为BoundedBuffer的内部类RingBuffer。 StripedBuffer实现模仿jdk中的java.util.concurrent.atomic.Striped64, 比如java.util.concurrent.atomic.LongAdder extends Striped64的并发累加器, 其实现中有多个long的累加器,可以并发累加,最后获取sum的时候将所有累加器sum起来即可。 除了支持并发写入,StripedBuffer还避免了扩容时的复制操作。
StripedBuffer的uml和原理示意图如下图: 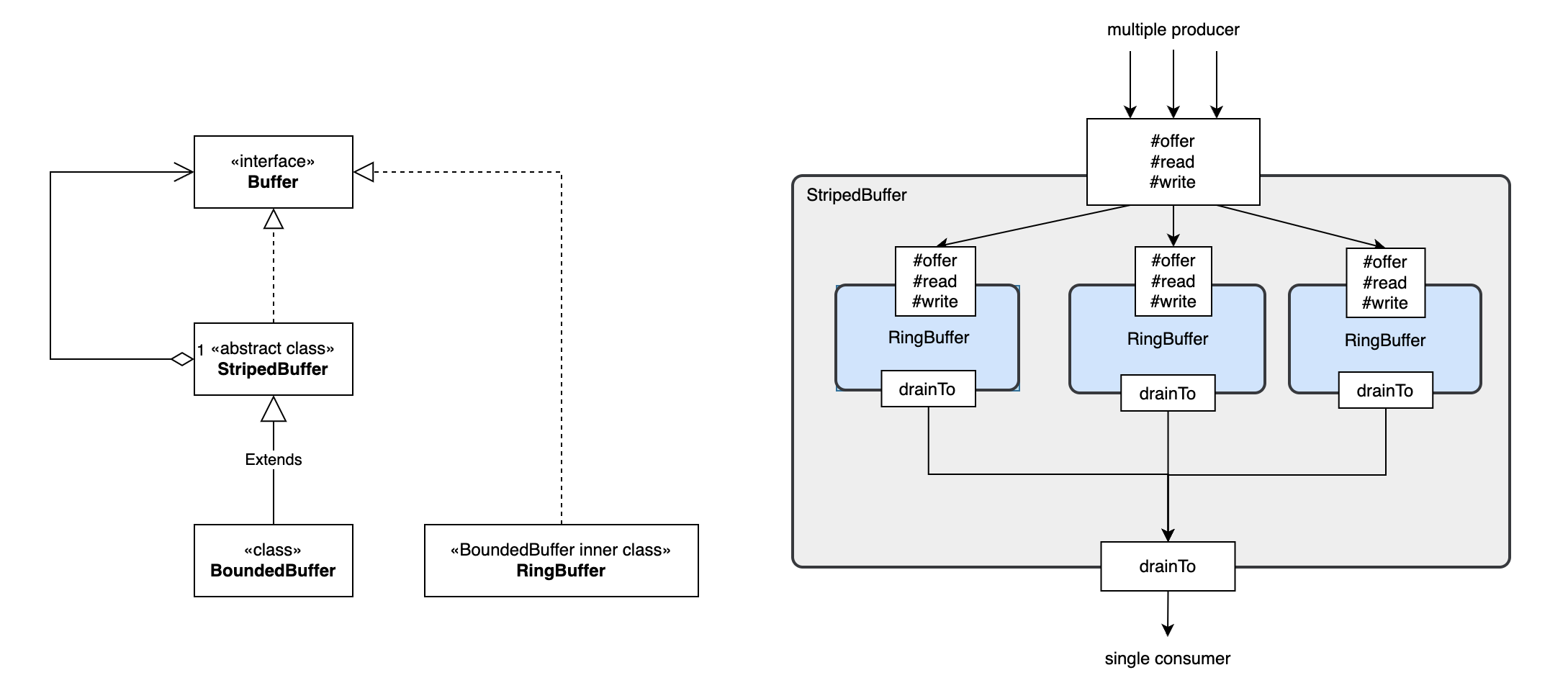
刨去预防false sharing 的 pad相关代码,RingBuffer也是通过双指针来对一个固定size的数组进行循环利用,简化格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
static final class RingBuffer<E> extends ... implements Buffer<E> {
static final VarHandle BUFFER = MethodHandles.arrayElementVarHandle(Object[].class);
static final VarHandle READ WRITE;
static {
...
READ = lookup.findVarHandle(BBHeader.ReadCounterRef.class, "readCounter", long.class);
WRITE = lookup.findVarHandle(BBHeader.ReadAndWriteCounterRef.class, "writeCounter", long.class);
...
}
// 一个RingBuffer固定16个元素
static final int BUFFER_SIZE = 16;
// mask,取RingBuffer数组index用
static final int MASK = BUFFER_SIZE - 1;
// 不直接使用,通过BUFFER字段调用
final Object[] buffer;
// 类似于写入指针,但这里通过counter表示,单调递增,且一定大于等于readCounter
// 不直接使用,通过WRITE字段调用
volatile long writeCounter;
// 类似于读取指针,但这里通过counter表示,单调递增,且一定小于等于writeCounter
// 不直接使用,通过READ字段调用
volatile long readCounter;
public RingBuffer(E e) {
buffer = new Object[BUFFER_SIZE];
// 写buffer[]的第0个index
BUFFER.set(buffer, 0, e);
// write计数器+1
WRITE.set(this, 1);
}
@Override
public int offer(E e) {
long head = readCounter;
long tail = writeCounterOpaque();
long size = (tail - head);
// 环形数组,读写counter>=16即满了
if (size >= BUFFER_SIZE) {
return Buffer.FULL;
}
// 没满先cas writeCounter,失败直接返回fail
if (casWriteCounter(tail, tail + 1)) {
// 计算index,
// 极端举例,tail = 18, head最小只能是3,
// 18 = 10010 和 1111做与 = 0010
// 此时会写入到index = 2的位置,因为head=3之前的元素已经被处理过了,可以覆盖,实现循环利用
int index = (int) (tail & MASK);
BUFFER.setRelease(buffer, index, e);
return Buffer.SUCCESS;
}
return Buffer.FAILED;
}
@Override
@SuppressWarnings("Varifier")
public void drainTo(Consumer<E> consumer) {
@Var long head = readCounter;
long tail = writeCounterOpaque();
long size = (tail - head);
// 特判
if (size == 0) {
return;
}
do {
// 读取下一个元素
int index = (int) (head & MASK);
var e = (E) BUFFER.getAcquire(buffer, index);
if (e == null) {
// write还没写进去,因为写入是先cas writeCounter再写入元素到数组,所以存在为null的情况
// not published yet
break;
}
BUFFER.setRelease(buffer, index, null);
consumer.accept(e);
head++;
} while (head != tail);
// readerCounter归位
setReadCounterOpaque(head);
}
...
}
}
那么StripedBuffer面对并发offer时,如何实现的呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
abstract class StripedBuffer<E> implements Buffer<E> {
@Override
public int offer(E e) {
// 计算一个hash值h,用于定位此次写入Buffer<E>[]的index
long z = mix64(Thread.currentThread().getId());
int increment = ((int) (z >>> 32)) | 1;
int h = (int) z;
int mask; // mask,用于根据hash值计算出对应的index
int result; // 结果,0成功 -1失败,1满了
BoundedBuffer.RingBuffer<E> buffer;
boolean uncontended = true; // 是否存在竞争,即RingBuffer的cas是否成功
Buffer<E>[] buffers = table;
if ((buffers == null) // 第一次buffers还没初始化,直接走到expandOrRetry
|| ((mask = buffers.length - 1) < 0) // 即buffers.length == 0,buffers还没初始化完成
|| ((buffer = (BoundedBuffer.RingBuffer<E>) buffers[h & mask]) == null) // 定位到的buffers[]的RingBuffer
// 实际执行插入到RingBuffer中,FAILED则expandOrRetry,如果FULL,则直接返回FULL,外层调用会主动调用drainTo
|| !(uncontended = ((result = buffer.offer(e)) != Buffer.FAILED))) {
// “扩容”或者重试
return expandOrRetry(e, h, increment, uncontended);
}
return result;
}
/**
* resize和create Buffers时cas的标志位
*/
volatile int tableBusy;
// 包含初始化、扩容、创建Buffer
final int expandOrRetry(E e, int h, int increment, boolean wasUncontended) {
int result = Buffer.FAILED;
boolean collide = false; // True if last slot nonempty
for (int attempt = 0; attempt < ATTEMPTS; attempt++) { // 重试3次, 3次是有含义的,往下看
Buffer<E>[] buffers;
Buffer<E> buffer;
int n;
if (((buffers = table) != null) && ((n = buffers.length) > 0)) { // buffers初始化了
if ((buffer = buffers[(n - 1) & h]) == null) { // 定位RingBuffer如果为null
if ((tableBusy == 0) && casTableBusy()) { // tableBusy标志位设置成功
boolean created = false;
try { // Recheck under lock
Buffer<E>[] rs;
int mask;
int j;
// 再次判断RingBuffer是否为空
if (((rs = table) != null) && ((mask = rs.length) > 0)
&& (rs[j = (mask - 1) & h] == null)) {
// 创建一个RingBuffer,调用BoundedBuffer#create
rs[j] = create(e);
created = true;
}
} finally {
tableBusy = 0;
}
if (created) {
result = Buffer.SUCCESS;
break;
}
continue; // Slot is now non-empty
}
collide = false;
} else if (!wasUncontended) {
// 走到这里只有在StripedBuffer的offer方法的if里的最后buffer#offer失败的情况
wasUncontended = true;
} else if ((result = buffer.offer(e)) != Buffer.FAILED) { // 【再次重试】
// RingBuffer插入SUCCESS或FULL则直接返回
break;
} else if ((n >= MAXIMUM_TABLE_SIZE) || (table != buffers)) {
// buffers已经到最大值或table已经不是最初的buffers(即经过Arrays.copyOf扩容)
collide = false; // At max size or stale
} else if (!collide) { // 上面【再次重试】还是失败,collide碰撞标记设为true
collide = true;
} else if ((tableBusy == 0) && casTableBusy()) {
// 走到这里是,先【再次重试】失败,然后到上面的if将collide设为true
// 然后下一次循环【再次重试】失败和后面的if判断失败就会走这里实施扩容
try {
if (table == buffers) {
// 扩容table,2倍
table = Arrays.copyOf(buffers, n << 1);
}
} finally {
tableBusy = 0;
}
collide = false;
// 扩容后不会重试offer,而是在下一次for循环offer插入,所以重试的ATTEMPTS==3
continue; // Retry with expanded table
}
// hash值变化增加一下
h += increment;
}
// 执行初始化
// 如果tableBusy标志位不是1,且cas设置为1成功
else if ((tableBusy == 0) && (table == buffers) && casTableBusy()) {
boolean init = false;
try { // Initialize table
if (table == buffers) {
Buffer<E>[] rs = new Buffer[1];
// create实际调用BoundedBuffer#create方法返回RingBuffer
rs[0] = create(e);
table = rs;
init = true;
}
} finally {
tableBusy = 0;
}
if (init) {
result = Buffer.SUCCESS;
break;
}
}
}
return result;
}
...
}
MpscGrowableArrayQueue
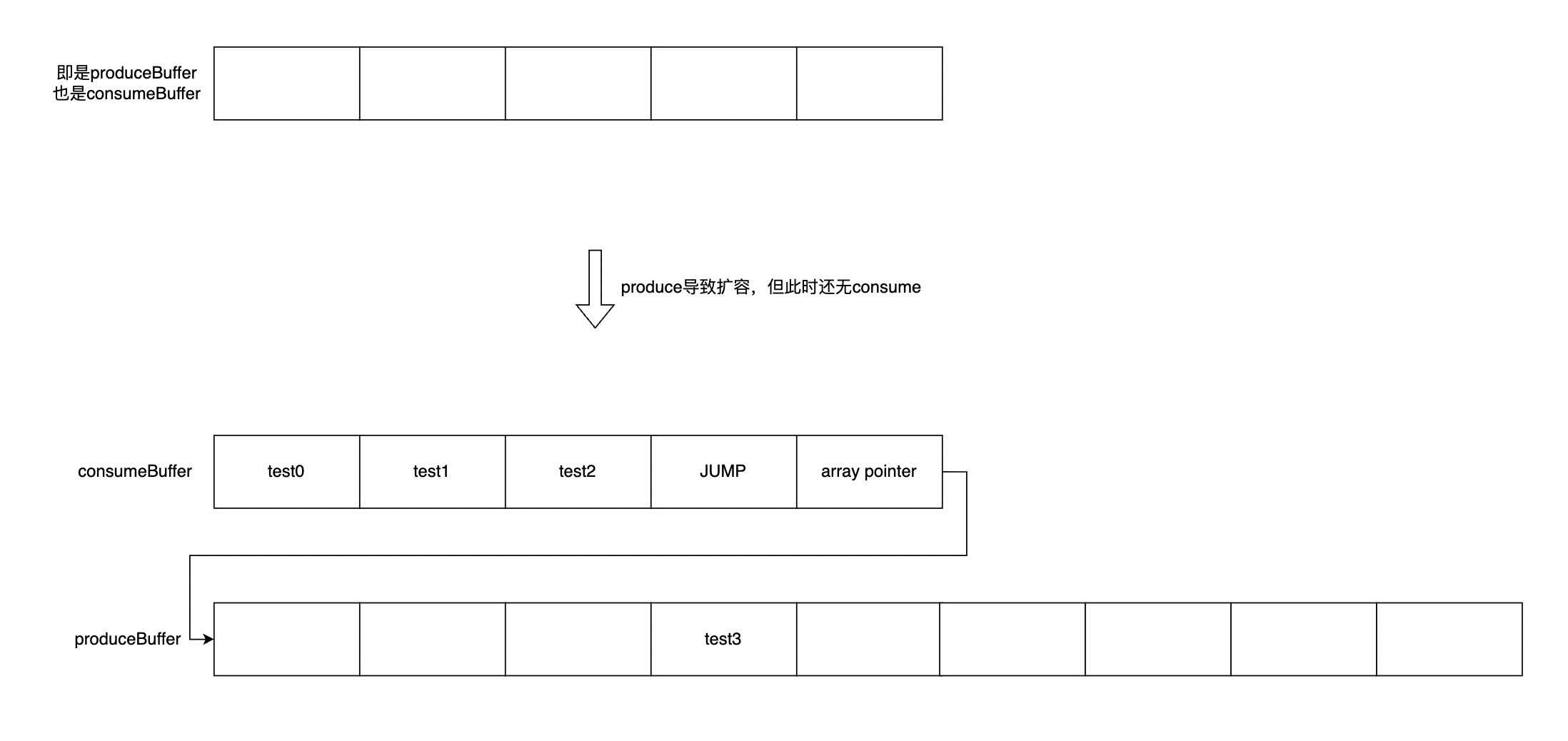
MpscGrowableArrayQueue优势是在扩容时不需要copy数组,只需要重新分配数组并使用指针链接 先来看下几个名词:
- producerBuffer: 写入元素数组
- consumerBuffer: 读取元素数组,当读取及时时可以和producerBuffer是同一个数组
- producerIndex(pIndex): 写入元素的数量 * 2,为什么*2 ?因为奇数表示扩容中,代码中很多数值都乘以2了,要注意辨别
- consumerIndex(cIndex): 读取元素的数量 * 2
- offset: buffer[]中的元素的index,可由 pIndex 和 cIndex 和mask 转化而来
(pIndex & mask) >> 1 - mask: 掩码,用于计算offset和capacity(实际大小,非乘以2的值),为n位1+末位0,如 6=110,14=1110,30=11110
- JUMP: 静态标识变量,放入buffer[]中,表示需要到nextBuffer的相同index找元素
- maxQueueCapacity:数组最大容量 * 2
MpscGrowableArrayQueue的数据结构和扩容方式如下图:
| 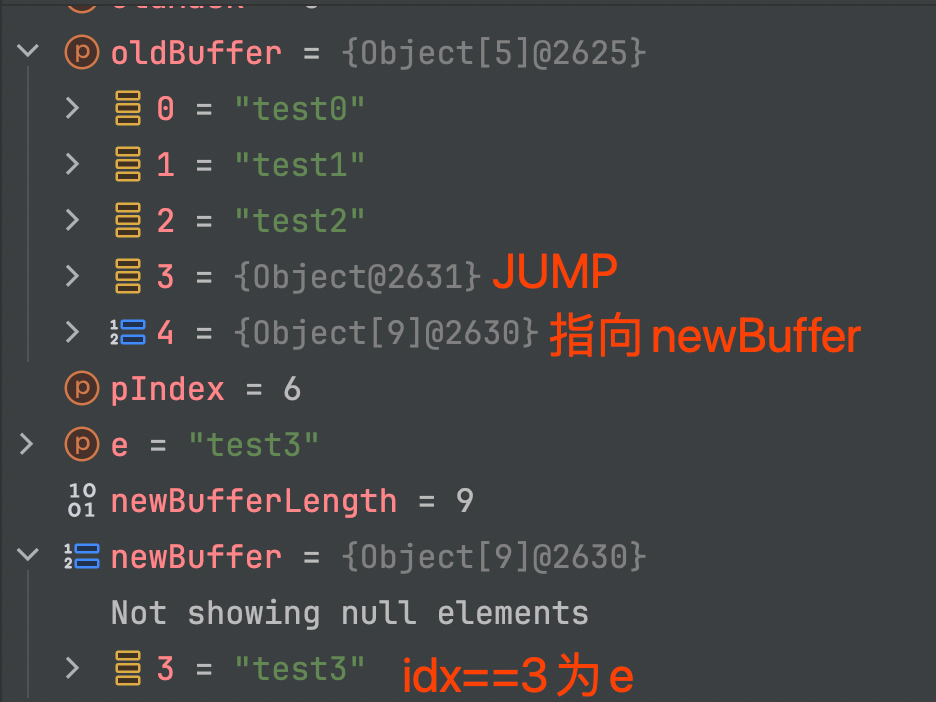 |
|  | |—————————————–|——————————————-|
| |—————————————–|——————————————-|
看下计算规则:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// initialCapacity为构造函数传入
// initialCap -> p2capacity: 6 -> 8, 7 -> 8, 8 -> 8, 9 -> 16
int p2capacity = ceilingPowerOfTwo(initialCapacity);
// 末位为0的掩码
// p2capacity -> mask(二进制表示) : 4 -> 110, 8 -> 1110, 16 -> 11110
long mask = (p2capacity - 1L) << 1;
// +1的是存放指向nextBuffer[]的指针
E[] buffer = allocate(p2capacity + 1);
// 扩容buffer[]的长度根据现有buffer[]的长度计算得来
int newSize = 2 * (buffer.length - 1) + 1
// 注意,buffer[]的length和capacity表示不同的东西
// length表示数组的长度
// capacity表示数组可存放元素的数量(不含JUMP 和nextBuffer指针)
protected long getCurrentBufferCapacity(long mask) {
// 根据构造函数中规则可知
// mask = (p2capacity - 1L) << 1 = 2 * p2capacity - 2; 这里p2Capacity真实没乘2的容量,是initialCapacity向上取最小的2的n次方
// curBufferLength = p2capacity + 1
// 又根据扩容规则 nextBufferLength = 2 * (curBufferLength - 1) + 1 = 2 * p2capacity + 1 = (mask + 2) + 1
// 所以每次扩容都是把 p2capacity * 2,然后再加一个指针的1
// 但是如果 p2capacity * 2 已经达到了 maxQueueCapacity,也就不需要预留向后扩容用的指针了
// 直接把原来存放指针的地方用来存放元素,扩大一个容量
return (mask + 2 == maxQueueCapacity) ? maxQueueCapacity : mask;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class MpscGrowableArrayQueue<E> extends ...BaseMpscLinkedArrayQueue... {
// 应理解为当前prodce过的元素的 count * 2,可以转化为producerBuffer的索引,通过VarHandle操作
protected long producerIndex;
protected long producerMask;
// 写入buffer
protected E[] producerBuffer;
protected volatile long producerLimit;
// 应理解为当前consume过的元素的 count * 2,可以转化为consumerBuffer的索引
protected long consumerIndex;
protected long consumerMask;
// 读取buffer,当消费及时时可以和producerBuffer是同一个数组
protected E[] consumerBuffer;
// 表示获取nextBuffer的相同index的元素
private static final Object JUMP = new Object();
protected final long maxQueueCapacity;
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
abstract class BaseMpscLinkedArrayQueue<E> ... {
...
BaseMpscLinkedArrayQueue(int initialCapacity) {
if (initialCapacity < 2) {
throw new IllegalArgumentException("Initial capacity must be 2 or more");
}
// 6 -> 8, 7 -> 8, 8 -> 8, 9 -> 16
int p2capacity = ceilingPowerOfTwo(initialCapacity);
// leave lower bit of mask clear
// 8 = 1000 -> 1000 - 1 = 0111 -> 0111 << 1 = 1110 = 14
// 0000 0000 0000 00
long mask = (p2capacity - 1L) << 1;
// need extra element to point at next array
E[] buffer = allocate(p2capacity + 1);
producerBuffer = buffer;
producerMask = mask;
consumerBuffer = buffer;
consumerMask = mask;
soProducerLimit(this, mask); // we know it's all empty to start with
}
@Override
public boolean offer(E e) {
if (e == null) {
throw new NullPointerException();
}
long mask; // mask 即 当前buffer的size
E[] buffer;
// pIndex表示两个含义:
// 1. 使用最后一位表示是否在扩容,最后一位为1(奇数)表示在扩容
// 2. 使用pIndex >> 2 即 pIndex/2 表示最新写入元素在buffer数组中的索引,后面代码称为offset
long pIndex;
while (true) {
// lv表示 volatile load (load + LoadLoad barrier)
long producerLimit = lvProducerLimit();
pIndex = lvProducerIndex(this);
// lower bit is indicative of resize, if we see it we spin until it's cleared
// 奇数表示正在扩容,自旋
if ((pIndex & 1) == 1) {
continue;
}
// mask/buffer may get changed by resizing -> only use for array access after successful CAS.
mask = this.producerMask;
buffer = this.producerBuffer;
// a successful CAS ties the ordering, lv(pIndex)-[mask/buffer]->cas(pIndex)
// 这里快速判断是否需要扩容,不需要再直接写入元素到现有buffer[]
if (producerLimit <= pIndex) {
// 内层
int result = offerSlowPath(mask, pIndex, producerLimit);
switch (result) {
case 0:
break;
case 1:
continue;
case 2:
return false;
case 3:
resize(mask, buffer, pIndex, e);
return true;
}
}
// 先cas更新pIndex
if (casProducerIndex(this, pIndex, pIndex + 2)) {
break;
}
}
// cas更新pIndex成功后再设置元素,这里的offset是才是数组的索引
long offset = modifiedCalcElementOffset(pIndex, mask);
// so表示set offset
soElement(buffer, offset, e);
return true;
}
/**
* We do not inline resize into this method because we do not resize on fill.
*/
// 此时pIndex <= producerLimit
private int offerSlowPath(long mask, long pIndex, long producerLimit) {
int result;
long cIndex = lvConsumerIndex(this);
long bufferCapacity = getCurrentBufferCapacity(mask);
result = 0; // 0 - goto pIndex CAS
if (cIndex + bufferCapacity > pIndex) {
if (!casProducerLimit(this, producerLimit, cIndex + bufferCapacity)) {
// 1表示重试
result = 1;
}
}
// pIndex和cIndex相差超过maxQueueCapacity了,即满了
// 注意这里maxQueueCapacity是2倍的bufferCapacity,即maxQueueCapacity = 2 * bufferCapacity,和pIndex逻辑一样
else if (availableInQueue(pIndex, cIndex) <= 0) {
// 2表示失败
result = 2;
}
// pIndex设置为奇数,表示正在扩容
else if (casProducerIndex(this, pIndex, pIndex + 1)) {
// 扩容
result = 3;
} else {
// 扩容失败,重试
result = 1;
}
return result;
}
@Override
protected long getCurrentBufferCapacity(long mask) {
// 根据构造函数中规则可知
// mask = (p2capacity - 1L) << 1 = 2 * p2capacity - 2; 这里p2Capacity真实没乘2的容量,是initialCapacity向上取最小的2的n次方
// curBufferLength = p2capacity + 1
// 又根据扩容规则 nextBufferLength = 2 * (curBufferLength - 1) + 1 = 2 * p2capacity + 1 = (mask + 2) + 1
// 所以每次扩容都是把 p2capacity * 2,然后再加一个指针的1
// 但是如果 p2capacity * 2 已经达到了 maxQueueCapacity,也就不需要预留向后扩容用的指针了
// 直接把原来存放指针的地方用来存放元素,扩大一个容量
return (mask + 2 == maxQueueCapacity) ? maxQueueCapacity : mask;
}
protected long availableInQueue(long pIndex, long cIndex) {
return maxQueueCapacity - (pIndex - cIndex);
}
/**
* poll只能单线程处理
*/
@Override
@SuppressWarnings({"CastCanBeRemovedNarrowingVariableType", "unchecked"})
public E poll() {
E[] buffer = consumerBuffer;
long index = consumerIndex;
long mask = consumerMask;
long offset = modifiedCalcElementOffset(index, mask);
Object e = lvElement(buffer, offset);// LoadLoad
if (e == null) {
if (index != lvProducerIndex(this)) {
// e当且仅当queue是空的
// 但仅仅通过 e==null 不能表示queue为空,得看producerIndex和consumerIndex的关系
// consumerIndex != producerIndex 且 e == null 说明有producer正在插入(插入是先cas pIndex再插入元素)
// 自旋
do {
e = lvElement(buffer, offset);
} while (e == null);
} else {
// 此时consumerIndex == producerIndex,说明都poll了,队列为空
return null;
}
}
if (e == JUMP) {
// JUMP到链接的下一个buffer
E[] nextBuffer = getNextBuffer(buffer, mask);
// 取array中相同的index的元素,并更新元素和consumerIndex
return newBufferPoll(nextBuffer, index);
}
// 更新元素
soElement(buffer, offset, null);
// 更新consumerIndex
soConsumerIndex(this, index + 2);
return (E) e;
}
/**
* This method assumes index is actually (index << 1) because lower bit is used for resize. This
* is compensated for by reducing the element shift. The computation is constant folded, so
* there's no cost.
*/
// index = 2 -> offset = 1, index = 4 -> offset = 2
static long modifiedCalcElementOffset(long index, long mask) {
return (index & mask) >> 1;
}
private void resize(long oldMask, E[] oldBuffer, long pIndex, E e) {
// 扩容规则
int newBufferLength = getNextBufferSize(oldBuffer);
E[] newBuffer = allocate(newBufferLength);
producerBuffer = newBuffer;
int newMask = (newBufferLength - 2) << 1;
producerMask = newMask;
// 计算buffer[]中的index,这里叫offset
long offsetInOld = modifiedCalcElementOffset(pIndex, oldMask);
long offsetInNew = modifiedCalcElementOffset(pIndex, newMask);
// set 元素
soElement(newBuffer, offsetInNew, e);// element in new array
// set newBuffer[]指针
soElement(oldBuffer, nextArrayOffset(oldMask), newBuffer);// buffer linked
...
// Invalidate racing CASs
// We never set the limit beyond the bounds of a buffer
soProducerLimit(this, pIndex + Math.min(newMask, availableInQueue));
// make resize visible to the other producers
soProducerIndex(this, pIndex + 2);
// INDEX visible before ELEMENT, consistent with consumer expectation
// make resize visible to consumer
soElement(oldBuffer, offsetInOld, JUMP);
}
// 扩容规则
@Override
protected int getNextBufferSize(E[] buffer) {
long maxSize = maxQueueCapacity / 2;
// maxQueueCapacity是实际capacity的2倍,所以这里buffer.length 肯定不大于 maxSize
if (buffer.length > maxSize) {
throw new IllegalStateException();
}
int newSize = 2 * (buffer.length - 1);
return newSize + 1;
}
}