树型结构数据存储实践
很多业务场景会遇到树形结构的数据,如公司的人员职级树、行政区划树等。 使用类似MySQL的数据库进行存储,需要将树形结构(二维)存储到行格式(一维)的db中。
本文介绍了树型结构数据存储的三种方式:Adjacency Table , Nested Set , Bridge Table (Closure Table)。
以下方法均基于场景: 设想一个职员团队树,节点中为职工工号id和职工名称,节点1指向2表示职工1属于职工2的团队: 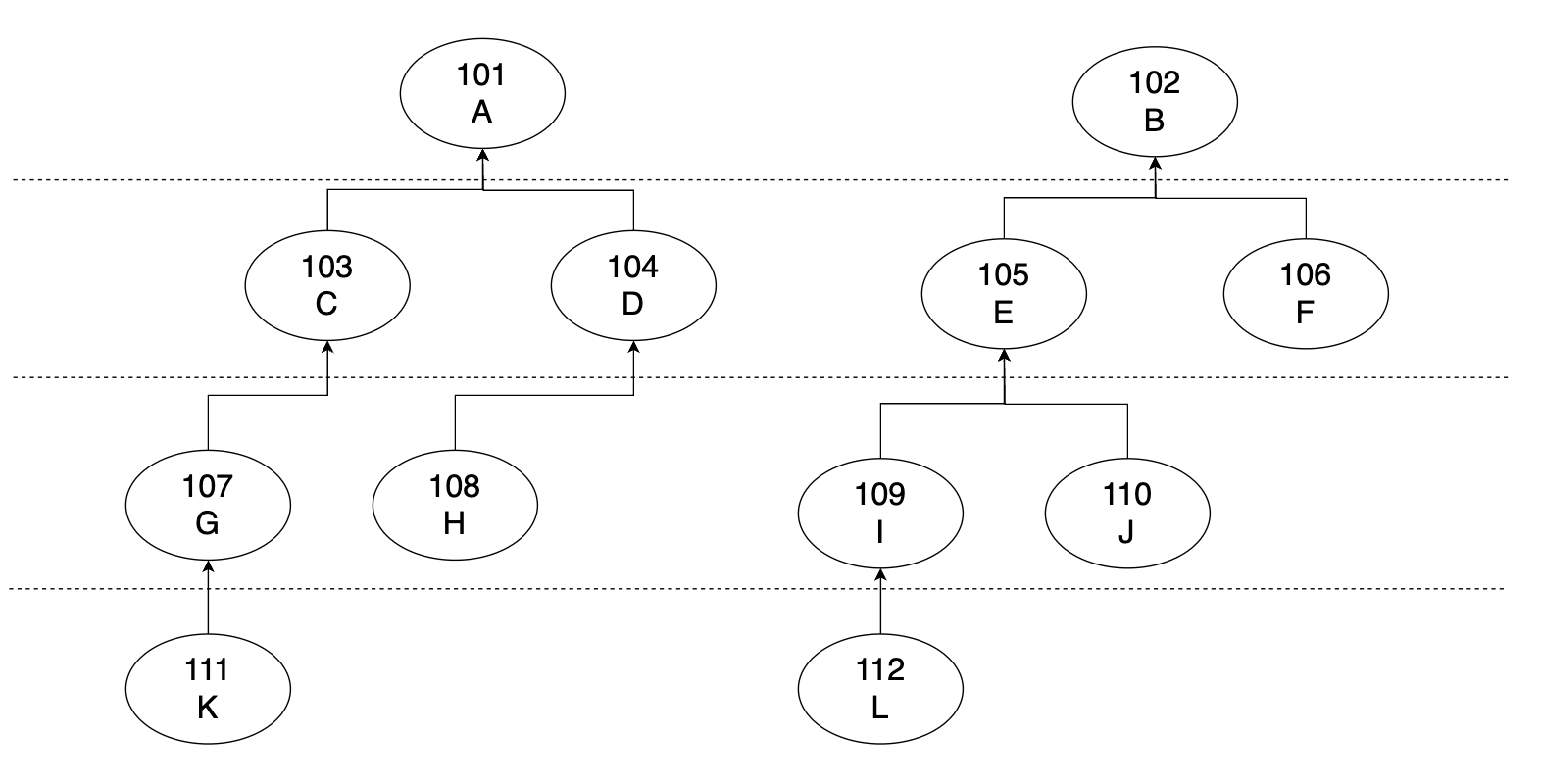
我们有如下的操作:
- 新增职工节点
- 删除职工节点
- 查询该职工节点下属的-1职工节点
- 查询该职工节点的所有下属职工节点
- 查询该职工节点的+1领导节点
- 查询该职工节点的所有领导节点
Adjacency Table
最简单的,我们构建一个邻接表,表中记录了当前职工id及其领导职工id(pid),数据组织结构如下:
| id 职工id | name 职工姓名 | pid 职工+1领导的职工id |
|---|---|---|
| 101 | A | null |
| 102 | B | null |
| 103 | C | 101 |
| 104 | D | 101 |
| … | … | … |
则我们可以生成如下的sql建表语句:
1
2
3
4
5
6
7
8
CREATE TABLE `employee_adjacency_table` (
`id` bigint NOT NULL COMMENT '职工id',
`name` varchar(64) NOT NULL COMMENT '职工姓名',
`pid` bigint COMMENT '+1领导的职工id',
`deleted` tinyint DEFAULT 0 COMMENT '软删标记',
PRIMARY KEY (`id`),
KEY `idx_pid` (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
新增职工节点
在节点108下插入叶子节点113:
1
INSERT INTO employee_adjacency_table (id,name,pid) VALUE (113,'M',108);
在105节点下插入非叶子节点113:
1
2
3
INSERT INTO employee_adjacency_table VALUE (113,'M',105);
-- 将105的-1子节点移植到113下
UPDATE employee_adjacency_table SET pid = 108 WHERE pid = 105;
删除职工节点
删除叶子节点111:
1
UPDATE employee_adjacency_table SET deleted = 1 where id = 111;
删除非叶子节点107,其叶子节点移植到107的+1领导节点下:
1
2
3
4
UPDATE employee_adjacency_table SET deleted = 1 where id = 107;
-- 查出107的领导节点,即105
SELECT pid FROM employee_adjacency_table WHERE id = 107 and deleted = 0 FOR UPDATE;
UPDATE employee_adjacency_table SET pid = 105 WHERE pid = 107;
查询该职工节点下属的-1职工节点
查询节点105下的-1子节点
1
SELECT * FROM employee_adjacency_table WHERE pid = 105 and deleted = 0
查询该职工节点的所有下属职工节点
查询节点105下的所有下属节点 需要每次查询一层数据,每次将查处的id作为pid查询条件继续查下一层,直到结果为空。
查询该职工节点的+1领导节点
查询节点109的+1领导节点
1
2
3
-- 查到109的+1领导节点,即105
SELECT pid FROM employee_adjacency_table WHERE id = 109 and deleted = 0;
SELECT * FROM employee_adjacency_table WHERE id = 105 and deleted = 0;
查询该职工节点的所有领导节点
查询节点112的所有领导节点 需要每次查询一层数据,每次将查处的pid作为id查询条件继续查上一层,直到pid为null。
优缺点及适用场景
优点:结构简单,节点变更简单 缺点:查询多层级节点效率低
一般树形数据会在服务启动时从数据库导入全量数据到缓存中。适合节点数量不大,变更少,变更实时性要求低的场景
Nested Set
相比与Adjacency Table 使用pid记录父级节点, Nested Set使用一对值(left & right)刻画树的父子关系。
以102为root的树为例,将其转化为Nested Set形式,每个节点转化为一个数值范围 [left, right],如下图所示: 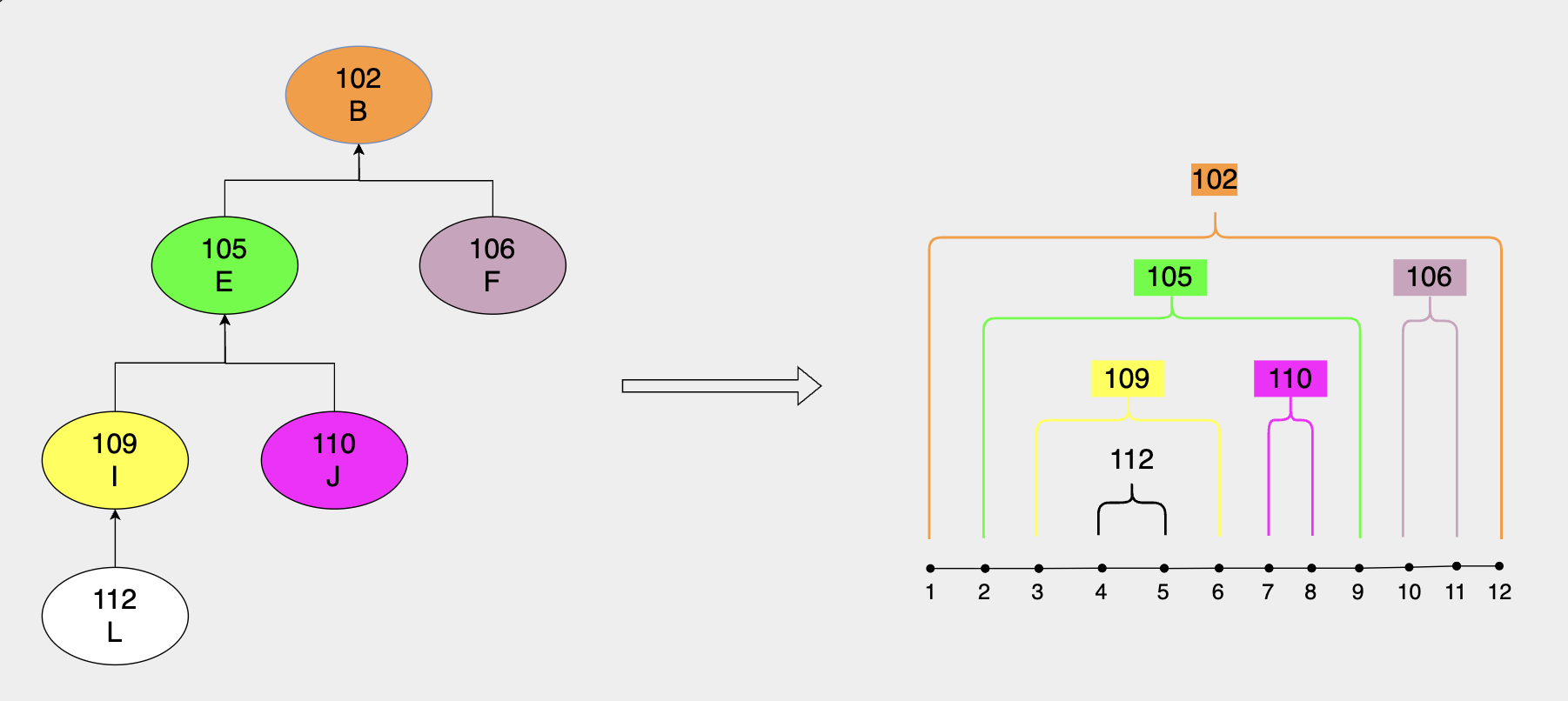
层级关系由数据范围的包含关系表示。比如工号102的职工的范围是 [1,12], 其下属职工105的范围是 [2,9],注意到叶子节点的left和right差值都是1。
则我们可以生成如下的sql建表语句:
1
2
3
4
5
6
7
8
9
10
CREATE TABLE employee_nested_set (
`id` bigint NOT NULL COMMENT '职工id',
`name` varchar(64) NOT NULL COMMENT '职工姓名',
`left` int NOT NULL,
`right` int NOT NULL,
`deleted` tinyint DEFAULT 0 COMMENT '软删标记',
PRIMARY KEY (`id`),
KEY `idx_left` (`left`),
KEY `idx_right` (`right`)
);
新增职工节点
我们要在职工110下面新增一个职工113,由于113是叶子结点,所以其left和right差值为1,且值必须在110的数值范围内,这样 只能将110的范围扩大,随之而来的是其右边值的统一扩大。
则新增的sql语句为(不能并发更新):
1
2
3
4
5
6
7
8
9
-- 找到节点110的左右值,即[7,8]
SELECT left,right FROM employee_nested_set where id = 110 and deleted = 0 FOR UPDATE;
-- 更新右侧left和right值
UPDATE employee_nested_set SET left = left + 2 WHERE left > 8 and deleted = 0;
UPDATE employee_nested_set SET right = right + 2 WHERE right >= 8 and deleted = 0;
-- 插入值范围
INSERT INTO employee_nested_set (id,name,left,right) VALUE (113, "M", 8 , 9);
我们要在职工110下面新增一个职工113,由于113是叶子结点,所以其left和right差值为1,且值必须在110的数值范围内,这样 只能将110的范围扩大,随之而来的是其右边值的统一扩大。
如果要在105和109之间插入新节点114呢?
1
2
3
4
5
6
7
-- 找到109的左右值,即 [3,6]
SELECT left,right FROM employee_nested_set WHERE id = 109 AND deleted = 0;
UPDATE employee_nested_set SET left = left + 1 , right = right + 1 WHERE left >= 3 and deleted = 0;
UPDATE employee_nested_set SET left = left + 1 , right = right + 1 WHERE left >= 6+1+1 and deleted = 0;
INSERT INTO employee_nested_set (id,name,left,right) VALUE (114,'N',3,8);
删除职工节点
比如删除节点109,109的从属节点继承到109的领导节点下:
1
2
3
4
5
6
-- 找到109的左右值,即 [3,6]
SELECT left,right FROM employee_nested_set WHERE id = 109 AND deleted = 1;
UPDATE employee_nested_set SET left = left - 1,right = right - 1 WHERE left BETWEEN 3 AND 6;
UPDATE employee_nested_set SET left = left - 1,right = right - 1 WHERE left > 7;
查询该职工节点下属的-1职工节点
很麻烦,比如找到105的-1职工节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
SELECT node.id, (COUNT(parent.id) - (sub_tree.depth + 1)) AS depth
FROM employee_nested_set AS node,
employee_nested_set AS parent,
employee_nested_set AS sub_parent,
(
SELECT node.id, (COUNT(parent.id) - 1) AS depth
FROM employee_nested_set AS node,
employee_nested_set AS parent
WHERE node.left BETWEEN parent.left AND parent.right
AND node.id = 105
GROUP BY node.name
ORDER BY node.left
)AS sub_tree
WHERE node.left BETWEEN parent.left AND parent.right
AND node.left BETWEEN sub_parent.left AND sub_parent.right
AND sub_parent.id = sub_tree.id
GROUP BY node.id
HAVING depth <= 1
ORDER BY node.left;
查询该职工节点的所有下属职工节点
很方便,比如找职工105下所有的职工id:
1
2
3
4
-- 找到105的left和right,即[2,9]
SELECT left,right FROM employee_nested_set WHERE id = 105 and deleted = 0;
-- 找到2和9之间的left的节点
SELECT id FROM employee_nested_set WHERE left BETWEEN 2 AND 9 and deleted = 0;
查询该职工节点的+1领导节点
找到职工105的+1领导节点,即102。
比较trick的写法:
1
2
3
4
5
6
SELECT parent.id
FROM employee_nested_set AS node, employee_nested_set AS parent
WHERE parent.left < node.left
AND parent.right > node.right
AND node.id =105
ORDER BY ( parent.right - parent.left ) ASC LIMIT 1;
查询该职工节点的所有领导节点
也很方便,比如找到职工110所有的领导节点:
1
2
3
4
5
-- 找到节点110的left和right,即[7,8]
SELECT left,right FROM employee_nested_set WEHERE id = 110 and deleted = 0;
-- 找到left<7 && right>8的节点即为其领导节点
SELECT id FROM employee_nested_set WHERE left < 7 and right > 8 and deleted = 0;
优缺点及适用场景
优点:适合查询所有下属节点的场景 缺点:数据从属关系不直观,变更操作复杂,时间复杂度高,且其他查询场景的sql语句复杂
适用于查询所有下属节点且节点变更频率低的场景,可以配合邻接表,邻接表作为变更入口,而Nested Set根据邻接表构造而成,查询所有下属节点的场景走NestSet
Bridge Table (Closure Table)
闭包表使用两张表记录数据,一张记录节点信息,一张记录ancestor节点到descendant节点之间的距离。
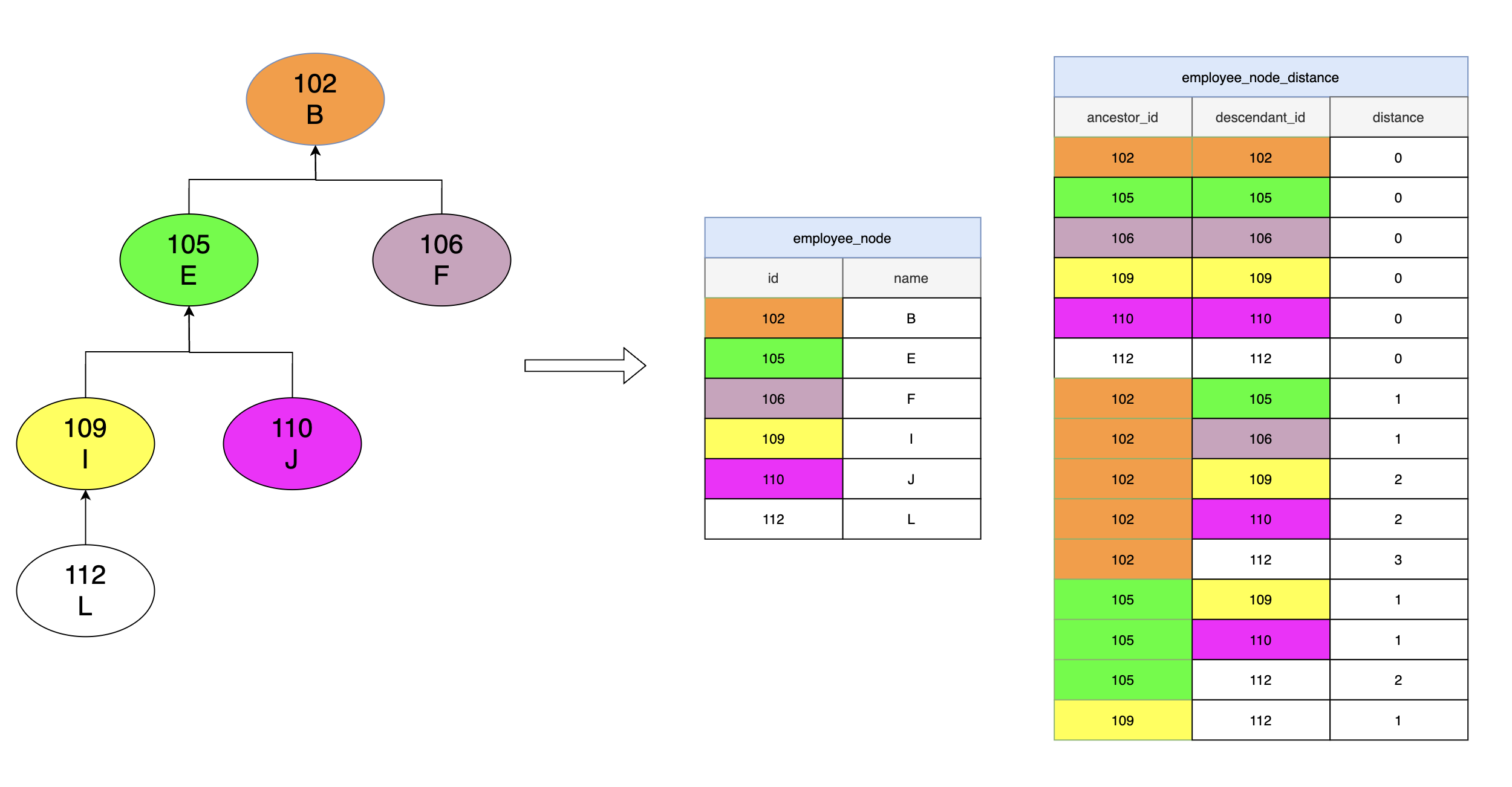
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
-- 节点信息表
CREATE TABLE `employee_node` (
`id` bigint NOT NULL,
`name` int NOT NULL,
`deleted` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
-- 节点与下属节点之间的距离表
CREATE TABLE `employee_node_distance` (
`id` bigint NOT NULL,
`ancestor_id` bigint NOT NULL,
`descendant_id` bigint NOT NULL,
`distance` int NOT NULL,
`deleted` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_anc_dist` (`ancestor_id`,`distance`),
KEY `idx_desc_dist` (`descendant_id`,`distance`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
新增职工节点
在节点110下插入叶子节点113:
1
2
3
4
5
6
7
8
9
INSERT INTO employee_node (id,name) VALUE (113,'M');
-- 查处descendant_id为110的所有ancestor_id和到110的距离
SELECT ancestor_id , distance FROM employee_node_distance
WHERE descendant_id = 110;
-- 根据上面查处的id和distance插入113的数据
INSERT INTO employee_node_distance (ancestor_id, descendant_id, distance)
VALUES (113,113,0),(ancestorIdOf110,113,distanceOf110+1);
在105节点和109节点间插入非叶子节点113:
1
2
3
4
5
6
7
8
9
10
11
12
INSERT INTO employee_node (id,name) VALUE (113,'M');
-- 查出105的所有领导节点
-- 插入113和领导节点的距离
-- 查处所有109的下属节点
-- 插入113和下属节点的距离
-- 根据109及其下属节点到他们领导节点的距离(+1)
删除职工节点
删除节点105:
1
查询该职工节点下属的-1职工节点
很方便,比如查询105的-1职工节点:
1
2
SELECT descendant_id FROM employee_node_distance
WHERE ancestor_id = 105 and distance = 1 and deleted = 0;
查询该职工节点的所有下属职工节点
很方便,比如查询105下所有下属节点:
1
2
SELECT descendant_id FROM employee_node_distance
WHERE ancestor_id = 105 and descendant_id != 105 and deleted = 0;
查询该职工节点的+1领导节点
很方便,比如查询109的+1领导节点,即105:
1
2
SELECT ancestor_id FROM employee_node_distance
WHERE descendant_id = 109 and distance = 1 and deleted = 0;
查询该职工节点的所有领导节点
很方便,比如查询112的所有领导节点
1
2
SELECT ancestor_id FROM employee_node_distance
WHERE descendant_id = 102 and ancestor_id != 102 and deleted = 0;
优缺点及适用场景
优点:满足各种场景查询,sql语句简单好理解 缺点:占用表空间大,空间复杂度O(N^2) N为节点个数,子节点变动需要更新所有领导节点数据
适用于节点数量少,但查询复杂的场景
参考: